June 7, 2024
Summary: in this tutorial, you will understand cost estimation for bitmap scan.
Table of Contents
PostgreSQL Bitmap Scan
While Index Scan is effective at high correlation, it falls short when the correlation drops to the point where the scanning pattern is more random than sequential and the number of page fetches increases. One solution here is to collect all the tuple IDs beforehand, sort them by page number, and then use them to scan the table. This is how Bitmap Scan, the second basic index scan method, works. It is available to any access method with the BITMAP SCAN property.
Let’s start with a little test setup:
CREATE TABLE foo (typ int, bar int, id1 int);
CREATE INDEX ON foo(typ);
CREATE INDEX ON foo(bar);
CREATE INDEX ON foo(id1);
INSERT INTO foo (typ, bar, id1)
SELECT
CAST(cos(2 * pi() * random()) * sqrt(-2 * ln(random())) * 100 AS integer),
n % 97, n % 101
FROM generate_series(1, 1000000) n;
VACUUM ANALYZE foo;
Consider the following plan:
EXPLAIN SELECT * FROM foo WHERE typ = 28;
QUERY PLAN
-------------------------------------------------------------------------------
Bitmap Heap Scan on foo (cost=110.39..3792.67 rows=3867 width=12)
Recheck Cond: (typ = 28)
-> Bitmap Index Scan on foo_typ_idx (cost=0.00..109.43 rows=3867 width=0)
Index Cond: (typ = 28)
(4 rows)
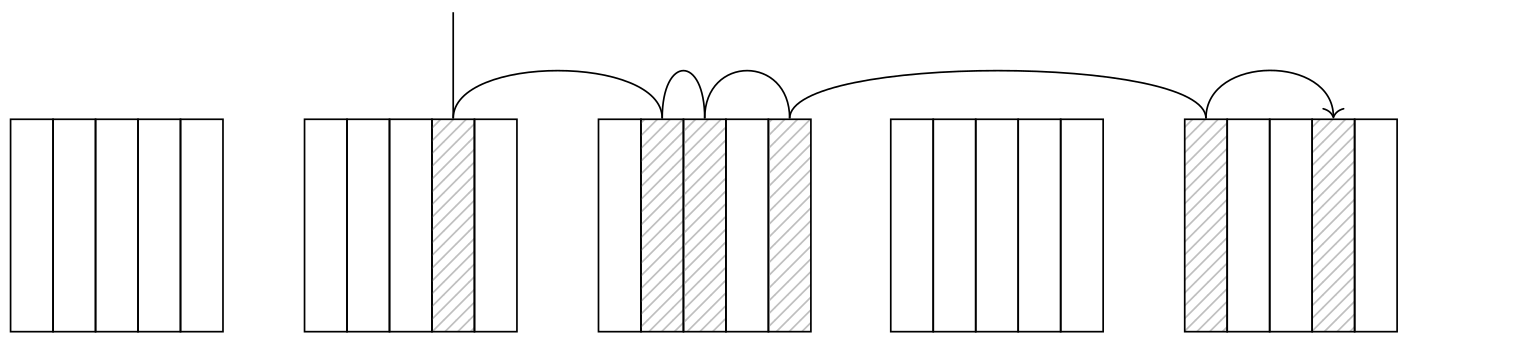
The Bitmap Scan operation is represented by two nodes: Bitmap Index Scan and Bitmap Heap Scan. The Bitmap Index Scan calls the access method, which generates the bitmap of all the tuple IDs.
A bitmap consists of multiple chunks, each corresponding to a single page in the table. The number of tuples on a page is limited due to a significant header size of each tuple (up to 256 tuples per standard page). As each page corresponds to a bitmap chunk, the chunks are created large enough to accommodate this maximum number of tuples (32 bytes per standard page).
The Bitmap Heap Scan node scans the bitmap chunk by chunk, goes to the corresponding pages, and fetches all the tuples there which are marked in the bitmap. Thus, the pages are fetched in ascending order, and each page is only fetched once.
The actual scan order is not sequential because the pages are probably not located one after another on the disk. The operating system’s prefetching is useless here, so Bitmap Heap Scan employs its own prefetching functionality (and it’s the only node to do so) by asynchronously reading the effective_io_concurrency of the pages. This functionality largely depends on whether or not your system supports the posix_fadvise function. If it does, you can set the parameter (on the table space level) in accordance with your hardware capabilities.
Map precision
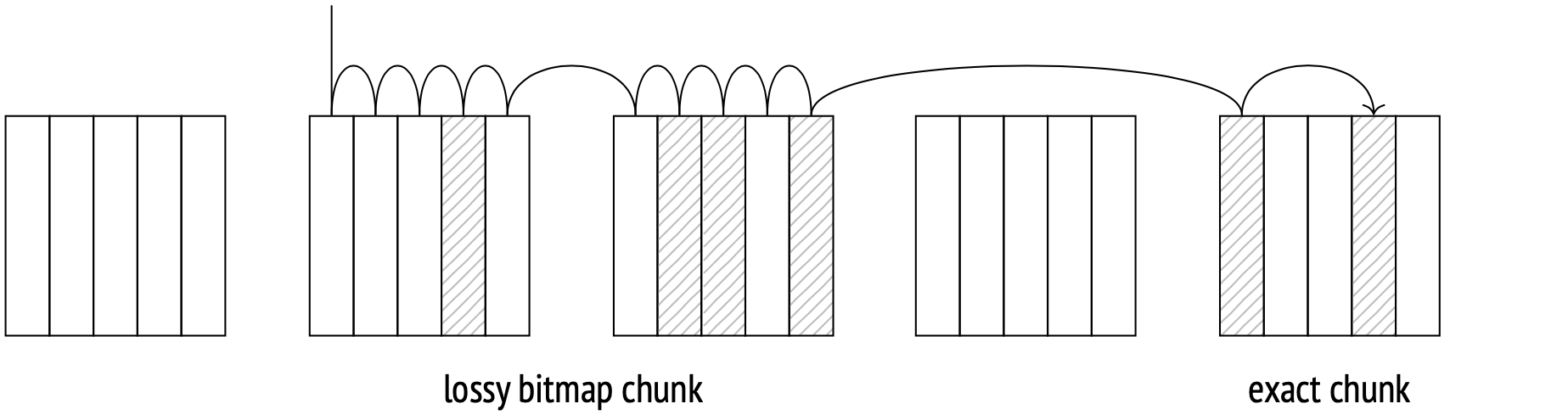
When a query requests tuples from a large number of pages, the bitmap of these pages can occupy a significant amount of local memory. The allowed bitmap size is limited by the work_mem parameter. If a bitmap reaches the maximum allowed size, some of its chunks start to get upscaled: each upscaled chunk’s bit is matched to a page instead of a tuple, and the chunk then covers a range of pages instead of just one. This keeps the bitmap size manageable while sacrificing some accuracy. You can check your bitmap accuracy with the EXPLAIN ANALYZE command:
EXPLAIN (analyze, costs off, timing off)
SELECT * FROM foo WHERE typ > 60;
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on foo (actual rows=273085 loops=1)
Recheck Cond: (typ > 60)
Heap Blocks: exact=3473
-> Bitmap Index Scan on foo_typ_idx (actual rows=273085 loops=1)
Index Cond: (typ > 60)
Planning time: 0.226 ms
Execution time: 42.928 ms
(7 rows)
In this case the bitmap was small enough to accommodate all the tuples data without upscaling. This is what we call an exact bitmap. If we lower the work_mem value, some bitmap chunks will be upscaled. This will make the bitmap lossy:
SET work_mem = '128kB';
EXPLAIN (analyze, costs off, timing off)
SELECT * FROM foo WHERE typ > 60;
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on foo (actual rows=273085 loops=1)
Recheck Cond: (typ > 60)
Rows Removed by Index Recheck: 545651
Heap Blocks: exact=862 lossy=2611
-> Bitmap Index Scan on foo_typ_idx (actual rows=273085 loops=1)
Index Cond: (typ > 60)
Planning time: 0.253 ms
Execution time: 76.703 ms
(8 rows)
When fetching a table page using an upscaled bitmap chunk, the planner has to recheck its tuples against the query conditions. This step is always represented by the Recheck Cond line in the plan, whether the checking actually takes place or not. The number of rows filtered out is displayed under Rows Removed by Index Recheck.
On large data sets, even a bitmap where each chunk was upscaled may still exceed the work_mem size. If this is the case, the work_mem limit is simply ignored, and no additional upscaling or buffering is done.
Bitmap operations
A query may include multiple fields in its filter conditions. These fields may each have a separate index. Bitmap Scan allows us to take advantage of multiple indexes at once. Each index gets a row version bitmap built for it, and the bitmaps are then ANDed and ORed together. Example:
EXPLAIN (costs off)
SELECT * FROM foo WHERE bar = 2 AND id1 = 4;
QUERY PLAN
----------------------------------------------
Bitmap Heap Scan on foo
Recheck Cond: ((id1 = 4) AND (bar = 2))
-> BitmapAnd
-> Bitmap Index Scan on foo_id1_idx
Index Cond: (id1 = 4)
-> Bitmap Index Scan on foo_bar_idx
Index Cond: (bar = 2)
(7 rows)
In this example the BitmapAnd node ANDs two bitmaps together.
When exact bitmaps are ANDed and ORed together, they remain exact (unless the resulting bitmap exceeds the work_mem limit). Any upscaled chunks in the original bitmaps remain upscaled in the resulting bitmap.
Cost estimation
Consider this Bitmap Scan example:
EXPLAIN SELECT * FROM foo WHERE bar = 2;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on foo (cost=115.47..5722.32 rows=10200 width=12)
Recheck Cond: (bar = 2)
-> Bitmap Index Scan on foo_bar_idx (cost=0.00..112.92 rows=10200 width=0)
Index Cond: (bar = 2)
(4 rows)
The planner estimates the selectivity here at approximately:
SELECT round(10200::numeric/reltuples::numeric, 4)
FROM pg_class WHERE relname = 'foo';
round
−−−−−−−−
0.0102
(1 row)
The total Bitmap Index Scan cost is calculated identically to the plain Index Scan cost, except for table scans:
SELECT round(
current_setting('random_page_cost')::real * pages +
current_setting('cpu_index_tuple_cost')::real * tuples +
current_setting('cpu_operator_cost')::real * tuples
)
FROM (
SELECT relpages * 0.0102 AS pages, reltuples * 0.0102 AS tuples
FROM pg_class WHERE relname = 'foo_bar_idx'
) c;
round
−−−−−−−
112
(1 row)
When bitmaps are ANDed and ORed together, their index scan costs are added up, plus a (tiny) cost of the logical operation.
The Bitmap Heap Scan I/O cost calculation differs significantly from the Index Scan one at perfect correlation. Bitmap Scan fetches table pages in ascending order and without repeat scans, but the matching tuples are no longer located neatly next to each other, so no quick and easy sequential scan all the way through. Therefore, the probable number of pages to be fetch increases.
This is illustrated by the following formula:

The fetch cost of a single page is estimated somewhere between seq_page_cost and random_page_cost, depending on the fraction of the total number of pages to be fetched.
WITH t AS (
SELECT relpages,
least(
(2 * relpages * reltuples * 0.0102) /
(2 * relpages + reltuples * 0.0102), relpages
) AS pages_fetched,
round(reltuples * 0.0102) AS tuples_fetched,
current_setting('random_page_cost')::real AS rnd_cost,
current_setting('seq_page_cost')::real AS seq_cost
FROM pg_class WHERE relname = 'foo'
)
SELECT pages_fetched,
rnd_cost - (rnd_cost - seq_cost) *
sqrt(pages_fetched / relpages) AS cost_per_page,
tuples_fetched
FROM t;
pages_fetched | cost_per_page | tuples_fetched
-------------------+--------------------+----------------
5248.543689320389 | 1.0440121655071204 | 10200
(1 row)
As usual, there is a processing cost for each scanned tuple to add to the total I/O cost. With an exact bitmap, the number of tuples fetched equals the number of table rows multiplied by the selectivity. When a bitmap is lossy, all the tuples on the lossy pages have to be rechecked:
This is why (in PostgreSQL 11 and higher) the estimate takes into account the probable fraction of lossy pages (which is calculated from the total number of rows and the work_mem limit).
The estimate also includes the total query conditions recheck cost (even for exact bitmaps). The Bitmap Heap Scan startup cost is calculated slightly differently from the Bitmap Index Scan total cost: there is the bitmap operations cost to account for. In this example, the bitmap is exact and the estimate is calculated as follows:
WITH t AS (
SELECT 1.0440121655071204 AS cost_per_page,
5248.543689320389 AS pages_fetched,
10200 AS tuples_fetched
),
costs(startup_cost, run_cost) AS (
SELECT
( SELECT round(
112 /* child node cost */ +
0.1 * current_setting('cpu_operator_cost')::real *
reltuples * 0.0102
)
FROM pg_class WHERE relname = 'foo_bar_idx'
),
( SELECT round(
cost_per_page * pages_fetched +
current_setting('cpu_tuple_cost')::real * tuples_fetched +
current_setting('cpu_operator_cost')::real * tuples_fetched
)
FROM t
)
)
SELECT startup_cost, run_cost, startup_cost + run_cost AS total_cost
FROM costs;
startup_cost | run_cost | total_cost
--------------+----------+------------
115 | 5607 | 5722
(1 row)