March 16, 2024
Summary: There are several limitations to parallel processing that should be kept in mind. In this tutorial, you will learn how to tune parallel query in PostgreSQL.
Table of Contents
Number of worker processes
The use of background worker processes is not limited to parallel query execution: they are used by the logical replication mechanism and may be created by extensions. The system can simultaneously run up to max_worker_processes background workers (8 by default).
Out of those, up to max_parallel_workers (also 8 by default) can be assigned to parallel query execution.
The number of allowed worker processes per leader process is set by max_parallel_workers_per_gather (2 by default).
You may choose to change these values based on several factors:
- Hardware configuration: the system must have spare processor cores.
- Table sizes: parallel queries are helpful with larger tables.
- Load type: the queries that benefit the most from parallel execution should be prevalent.
These factors are usually true for OLAP systems and false for OLTPs.
The planner will not even consider parallel scanning unless it expects to read at least min_parallel_table_scan_size of data (8MB by default).
Below is the formula for calculating the number of planned worker processes:
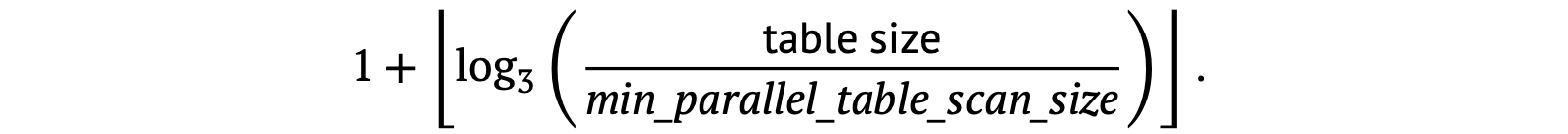
In essence, every time the table size triples, the planner adds one more parallel worker. Here’s an example table with the default parameters.
| Table, MB | Number of workers |
|---|---|
| 8 | 1 |
| 24 | 2 |
| 72 | 3 |
| 216 | 4 |
| 648 | 5 |
| 1944 | 6 |
The number of workers can be explicitly set with the table storage parameter parallel_workers.
The number of workers will still be limited by the max_parallel_workers_per_gather parameter, though.
Let’s query a small 20MB table. Only one worker process will be planned and created (see Workers Planned and Workers Launched):
CREATE TABLE testpar (id integer, str text);
INSERT INTO testpar (id, str)
SELECT i, repeat(chr(65 + mod(i, 26)), 64) as str
FROM generate_series(1, 240000) AS s(i);
ANALYZE testpar;
SELECT pg_size_pretty(pg_table_size('testpar'));
pg_size_pretty
----------------
20 MB
(1 row)
EXPLAIN (analyze, costs off, timing off)
SELECT count(*) FROM testpar;
QUERY PLAN
-----------------------------------------------------------------------------
Finalize Aggregate (actual rows=1 loops=1)
-> Gather (actual rows=2 loops=1)
Workers Planned: 1
Workers Launched: 1
-> Partial Aggregate (actual rows=1 loops=2)
-> Parallel Seq Scan on testpar (actual rows=120000 loops=2)
Planning time: 3.569 ms
Execution time: 72.964 ms
(8 rows)
Now let’s query a 98MB table. The system will create only two workers, obeying the max_parallel_workers_per_gather limit.
INSERT INTO testpar (id, str)
SELECT i, repeat(chr(65 + mod(i, 26)), 64) as str
FROM generate_series(240001, 1200000) AS s(i);
ANALYZE testpar;
SELECT pg_size_pretty(pg_table_size('testpar'));
pg_size_pretty
----------------
98 MB
(1 row)
EXPLAIN (analyze, costs off, timing off)
SELECT count(*) FROM testpar;
QUERY PLAN
-----------------------------------------------------------------------------
Finalize Aggregate (actual rows=1 loops=1)
-> Gather (actual rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (actual rows=1 loops=3)
-> Parallel Seq Scan on testpar (actual rows=400000 loops=3)
Planning time: 0.149 ms
Execution time: 108.843 ms
(8 rows)
If the limit is increased, three workers are created:
SET max_parallel_workers_per_gather = 4;
EXPLAIN (analyze, costs off, timing off)
SELECT count(*) FROM testpar;
QUERY PLAN
-----------------------------------------------------------------------------
Finalize Aggregate (actual rows=1 loops=1)
-> Gather (actual rows=4 loops=1)
Workers Planned: 3
Workers Launched: 3
-> Partial Aggregate (actual rows=1 loops=4)
-> Parallel Seq Scan on testpar (actual rows=300000 loops=4)
Planning time: 0.122 ms
Execution time: 113.670 ms
(8 rows)
If there are more planned workers than available worker slots in the system when the query is executed, only the available number of workers will be created.
Non-parallelizable queries
Not every query can be parallelized. These are the types of non-parallelizable queries:
-
Queries that modify or lock data (
UPDATE,DELETE,SELECT FOR UPDATEetc.).In PostgreSQL 11, such queries can still execute in parallel when called within commands
CREATE TABLE AS,SELECT INTOandCREATE MATERIALIZED VIEW(and in version 14 and higher also withinREFRESH MATERIALIZED VIEW).All
INSERToperations will still execute sequentially even in these cases, however. -
Any queries that can be suspended during execution. Queries inside a cursor, including those in PL/pgSQL FOR loops.
-
Queries that call
PARALLEL UNSAFEfunctions. By default, this includes all user-defined functions and some of the standard ones. You can get the complete list of unsafe functions from the system catalog:SELECT * FROM pg_proc WHERE proparallel = 'u'; -
Queries from within functions called from within an already parallelized query (to avoid creating new background workers recursively).
Future PostgreSQL versions may remove some of these limitations. Version 12, for example, added the ability to parallelize queries at the Serializable isolation level.
There are several possible reasons why a query will not run in parallel:
- It is non-parallelizable in the first place.
- Your configuration prevents the creation of parallel plans (including when a table is smaller than the parallelization threshold).
- The parallel plan is more costly than a sequential one.
If you want to force a query to be executed in parallel — for research or other purposes — you can set the parameter force_parallel_mode on. This will make the planner always produce parallel plans, unless the query is strictly non-parallelizable:
TRUNCATE testpar;
INSERT INTO testpar (id, str)
SELECT i, repeat(chr(65 + mod(i, 26)), 64) as str
FROM generate_series(1, 50000) AS s(i);
ANALYZE testpar;
SELECT pg_size_pretty(pg_table_size('testpar'));
pg_size_pretty
----------------
4200 kB
(1 row)
EXPLAIN SELECT * FROM testpar;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on testpar (cost=0.00..1021.00 rows=50000 width=69)
(1 row)
SET force_parallel_mode = on;
EXPLAIN SELECT * FROM testpar;
QUERY PLAN
---------------------------------------------------------------------
Gather (cost=1000.00..7021.00 rows=50000 width=69)
Workers Planned: 1
Single Copy: true
-> Seq Scan on testpar (cost=0.00..1021.00 rows=50000 width=69)
(4 rows)
Parallel restricted queries
In general, the benefit of parallel planning depends mostly on how much of the plan is parallel-compatible. There are, however, operations that technically do not prevent parallelization, but can only be executed sequentially and only by the leader process. In other words, these operations cannot appear in the parallel section of the plan, below Gather.
Let’s start with a little test setup:
TRUNCATE testpar;
INSERT INTO testpar (id, str)
SELECT i, repeat(chr(65 + mod(i, 26)), 64) as str
FROM generate_series(1, 240000) AS s(i);
ANALYZE testpar;
Non-expandable subqueries. A basic example of an operation containing non-expandable subqueries is a common table expression scan (the CTE Scan node below):
EXPLAIN (costs off)
WITH t AS MATERIALIZED (
SELECT * FROM testpar
)
SELECT count(*) FROM t;
QUERY PLAN
-----------------------------
Aggregate
CTE t
-> Seq Scan on testpar
-> CTE Scan on t
(4 rows)
If the common table expression is not materialized (which became possible only in PostgreSQL 12 and higher), then there is no CTE Scan node and no problem.
The expression itself can be processed in parallel, if it’s the quicker option.
EXPLAIN (costs off)
WITH t AS MATERIALIZED (
SELECT count(*) FROM testpar
)
SELECT * FROM t;
QUERY PLAN
--------------------------------------------------------
CTE Scan on t
CTE t
-> Finalize Aggregate
-> Gather
Workers Planned: 1
-> Partial Aggregate
-> Parallel Seq Scan on testpar
(7 rows)
Another example of a non-expandable subquery is a query with a SubPlan node.
EXPLAIN (costs off)
SELECT *
FROM flights f
WHERE f.scheduled_departure > ( -- SubPlan
SELECT min(f2.scheduled_departure)
FROM flights f2
WHERE f2.aircraft_code = f.aircraft_code
);
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights f
Filter: (scheduled_departure > (SubPlan 1))
SubPlan 1
−> Aggregate
−> Seq Scan on flights f2
Filter: (aircraft_code = f.aircraft_code)
(6 rows)
The first two rows display the plan of the main query: scan the flights table and filter each row. The filter condition includes a subquery, the plan of which follows the main plan. The SubPlan node is executed multiple times: once per scanned row, in this case.
The Seq Scan parent node cannot be parallelized because it needs the SubPlan output to proceed.
The last example is executing a non-expandable subquery represented by an InitPlan node.
EXPLAIN (costs off)
SELECT *
FROM flights f
WHERE f.scheduled_departure > ( -- SubPlan
SELECT min(f2.scheduled_departure) FROM flights f2
WHERE EXISTS ( -- InitPlan
SELECT *
FROM ticket_flights tf
WHERE tf.flight_id = f.flight_id
)
);
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights f
Filter: (scheduled_departure > (SubPlan 2))
SubPlan 2
−> Finalize Aggregate
InitPlan 1 (returns $1)
−> Seq Scan on ticket_flights tf
Filter: (flight_id = f.flight_id)
−> Gather
Workers Planned: 1
Params Evaluated: $1
−> Partial Aggregate
−> Result
One−Time Filter: $1
−> Parallel Seq Scan on flights f2
(14 rows)
Unlike a SubPlan, an InitPlan node executes only once (in this case, once per SubPlan 2 execution).
The InitPlan node’s parent can’t be parallelized, but nodes that use InitPlan output can, as illustrated here.
Temporary tables. Temporary tables can only be scanned sequentially because only the leader process has access to them.
CREATE TEMPORARY TABLE testpar_tmp AS SELECT * FROM testpar;
EXPLAIN (costs off)
SELECT count(*) FROM testpar_tmp;
QUERY PLAN
-------------------------------
Aggregate
-> Seq Scan on testpar_tmp
(2 rows)
Parallel restricted functions. Calls of functions labeled as PARALLEL RESTRICTED are only allowed within the sequential part of the plan. You can find the list of the restricted functions in the system catalog:
SELECT * FROM pg_proc WHERE proparallel = 'r';
Only label your own functions PARALLEL RESTRICTED (not to mention PARALLEL SAFE) after thoroughly studying the existing limitations and with great care.