由 John Doe 九月 2, 2024
摘要:在本文中,您将学习如何在 PostgreSQL 中使用顺序 UUID 生成器。
目录
介绍
UUID 是一种流行的标识符数据类型 – 它们是不可预测的,或者全局唯一(或至少不太可能发生冲突)并且很容易生成。传统的基于序列的主键不会提供任何这些特性,这使得它们不适用于公共标识符,而 UUID 很自然地解决了这个问题。
但也有缺点 – 与传统的顺序标识符相比,它们可能会使访问模式更加随机,导致 WAL 写入放大等。因此,让我们看看生成顺序 UUID 的扩展,以及它如何减少使用 UUID 的负面后果。
假设我们将行插入到一个具有 UUID 主键的表中(因此会有一个唯一索引),并且 UUID 会生成为随机值。在表中,行可以简单地附加到末尾,这样开销非常低。但是索引呢?对于索引排序的问题,数据库对于新条目插入到何处几乎没有选择 - 它必须进入索引中的特定位置。由于 UUID 值是随机生成的,因此位置将是随机的,所有索引页的分布都是均匀的。
这很遗憾,因为它不匹配自适应缓存管理算法 – 没有一组 “经常” 访问的页面,我们可以保存在内存中。如果索引大于内存,则缓存命中率(页面缓存和共享缓冲区)注定会很差。对于小型索引,您可能并不那么关心。
此外,这种随机写入访问模式会增加生成的 WAL 日志量,因为每次在检查点后首次修改页面时都必须执行全页写入。(这里有一个反馈循环,随着 FPI 增加 WAL 日志量,会更频繁地触发检查点 - 这又会导致生成更多的 FPI,……)
当然,UUID 也会影响读取模式。应用程序通常访问相当有限的最近数据子集。例如,电子商务网站主要关注过去几天的订单,很少访问超出此时间窗口的数据。这与顺序标识符一起工作得相当自然(记录在表和索引中都会有很好的位置),但 UUID 的随机性与此相矛盾,会导致缓存命中率不佳。
这些问题(尤其是写入放大)是使用 UUID 时常见的问题,并且不时地会出现在我们的邮件讨论列表中。例如,请参阅 Re: uuid, COMB uuid, distributed farms,、Indexes on UUID – Fragmentation Issue 或 Sequential UUID Generation。
让 UUID 有点顺序性
那么,我们如何在尽可能多地保留 UUID 优势的同时改善这种情况呢?如果我们坚持使用完全随机的 UUID 值,我们几乎无能为力。那么,如果我们放弃完美的随机性,而是让 UUID 稍微顺序一点呢?
注意:当然,这并不是一个全新的想法。这其实是维基百科 UUID 页面上描述的 COMB,并且 Jimmy Nilsson 在将 GUID 作为主键的代价中对此进行了详细描述。MSSQL 实现了一个变体,叫 newsequentialid(在内部调用 UuidCreateSequential)。在 sequential-uuids 扩展中实现并在此处介绍的解决方案,是为 PostgreSQL 量身定制的一个变体。
例如,一个(非常)简单的 UUID 生成器可能会从一个序列生成一个 64 位值,并附加额外的 64 个随机位。或者我们可以使用 32 位 unix 时间戳,并附加 96 个随机位。这些是朝着正确方向迈出的步骤,用顺序模式取代随机访问模式。但这里有一些缺陷。
首先,虽然这些值非常不可预测(64 个随机位使猜测变得相当困难),但由于顺序部分,相当多的信息泄漏。我们可以确定值的生成顺序或者值的生成时间。其次,完美的顺序模式也有缺点 – 例如,如果你删除历史数据,你最终可能会在索引中浪费相当多的空间,因为没有新项目会被路由到那些大部分为空的索引页面。
所以 sequential-uuids 扩展的作用要精细一些。该值不会生成完美顺序的前缀,而是在一段时间内是连续的,但也会偶尔换行。包装消除了可预测性(不再能够决定生成两个 UUID 的顺序或时间),并增加了 UUID 中的随机性(因为前缀更短)。
当使用序列(就像 nextval)时,前缀值在生成一定数量的 UUID 后定期递增,最后在一定数量的块后会回绕。例如,我们使用 2 位前缀(即 64k 个可能的前缀),在生成 256 个 UUID 后递增,这意味着在每生成 16M 数量的 UUID 后回绕。所以 prefix 的计算方式如下:
prefix := (nextval('s') / block_size) % block_count
前缀长度取决于block_count。对于 64k 的批数,我们只需要 2 位,其余 112 位是随机的。
对于基于时间戳的 UUID 生成器,前缀会定期递增,例如每 60 秒递增一次(或任何任意间隔,具体取决于您的应用程序)。在一定数量的此类增量之后,前缀将回绕并从头开始。前缀公式类似于基于序列的公式:
prefix := (EXTRACT(epoch FROM clock_timestamp()) / interval_length) % block_count
对于 64k 的批数,我们只需要 2 位(就像基于序列的生成器一样),其余的 112 位是随机的。前缀每 ~45 天环绕一次。
该扩展将其实现为两个简单的 SQL 调用函数:
uuid_sequence_nextval(sequence, block_size, block_count)uuid_time_nextval(interval_length, block_count)
有关更多详细信息,请参阅 README。
基准测试
是时候进行一个小的基准测试了,来演示下这些顺序 UUID 能如何提升访问模式。这里使用了一个存储设备相当弱的系统 (3 x 7200k SATA RAID) – 这是有意为之的,因为它可以让 I/O 模式的变化变得明显。该测试是非常简单的INSERT,插入一个带有单个 UUID 列的表,在表上面有一个UNIQUE索引。我们按三种数据集大小来测试 – 小型(空表)、中型(适合内存量)和大型(超出内存量)。
这些测试比较了四个 UUID 生成器:
- 随机:
uuid_generate_v4() - 时间:
uuid_time_nextval(interval_length := 60, interval_count := 65536) - 序列 (256):
uuid_sequence_nextval(s, block_size := 256, block_count := 65536) - 序列 (64k):
uuid_sequence_nextval(s, block_size := 65536, block_count := 65536)
4 小时运行的总体结果(每秒事务数)如下所示:
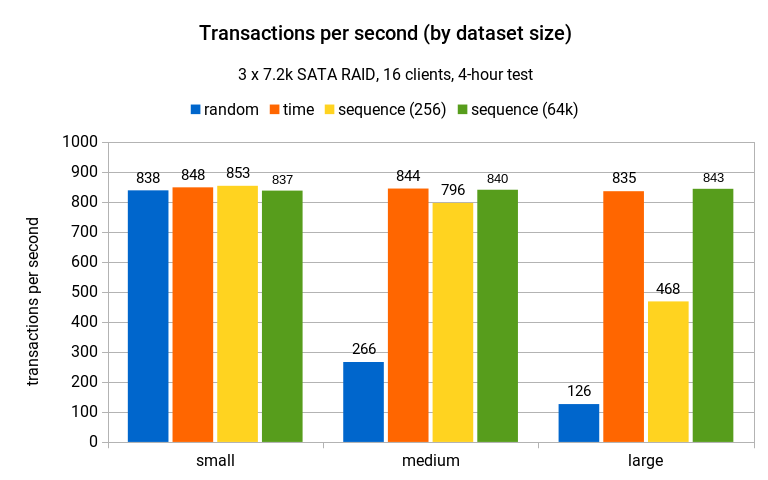
对于小型数据集,几乎没有区别 – 共享缓冲区 (4 GB) 可以容纳这些数据,因此不会因数据不断被驱逐而产生 I/O 浪费。
对于中型数据集(大于共享缓冲区内存量,但内存中仍然可以容纳这些数据),情况发生了很大变化,随机 UUID 生成器下降到原始吞吐量的 30% 以下,而其他生成器几乎保持了性能的稳定。
在大型数据集上,随机 UUID 生成器的吞吐量进一步下降,而时间和序列 (64k) 生成器保持了与小型数据集相同的吞吐量。序列 (256) 生成器的吞吐量下降了大约 1/2 – 发生这种情况是因为它非常频繁地增加前缀,并且导致修改的索引页比序列 (64k) 多得多,这将会在后面展示。但由于顺序行为,它仍然比随机模式快得多。
WAL 写入放大 / 小型数据集
如前所述,随机 UUID 的一个问题是,写入 WAL 的许多全页镜像(FPI)引起的写入放大。那么,让我们看看它在最小的数据集上是什么样子的。蓝色条表示 FPI 所占的 WAL 量(以 MB 为单位),而橙色条表示常规 WAL 记录所占的 WAL 量。
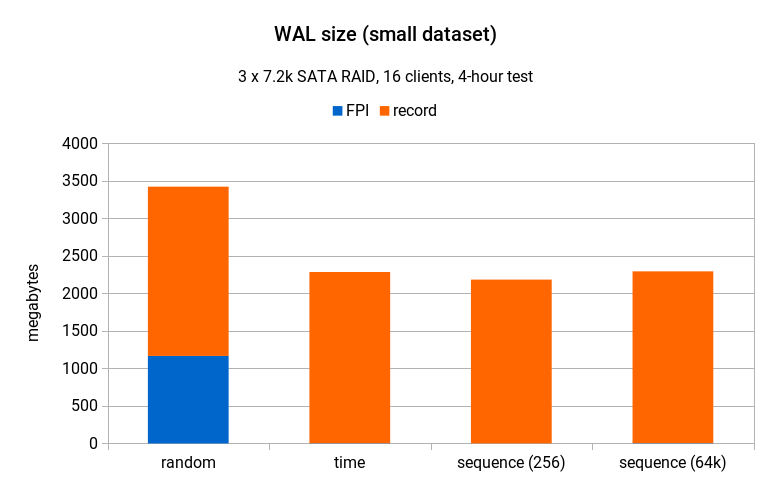
差异是显而易见的,尽管产生的 WAL 总量的变化并不大(并且对吞吐量的影响可以忽略不计,因为共享缓冲区可以容纳数据集,因此没有压力/强制驱逐)。虽然存储设备较差,但它可以很好地处理顺序写入,尤其是在这种速度下(4 小时内为 3.5GB)。
WAL 写入放大 / 中型数据集
在中型数据集上(与小型数据集相比,随机模式的吞吐量下降到了不到 30%),差异要明显得多。
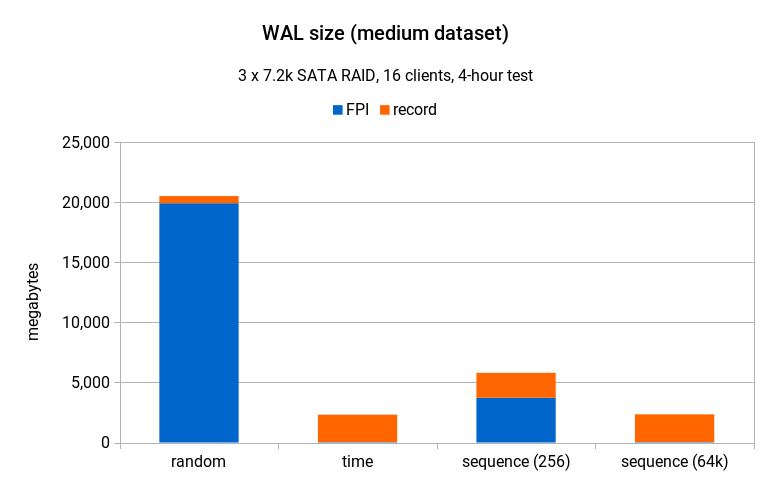
使用随机生成器,测试生成了超过 20GB 的 WAL,其中绝大多数是由于 FPI 造成的。时间和序列 (256) 生成器只产生了大约 2.5GB 的 WAL,而序列 (64k) 产生了大约 5GB。
但是请注意 - 这张图表实际上非常具有误导性,因为它比较了吞吐量非常不同的测试数据(260 TPS 对比 840 TPS)。将数字缩放到与随机模式相同的吞吐量后,图表如下所示:
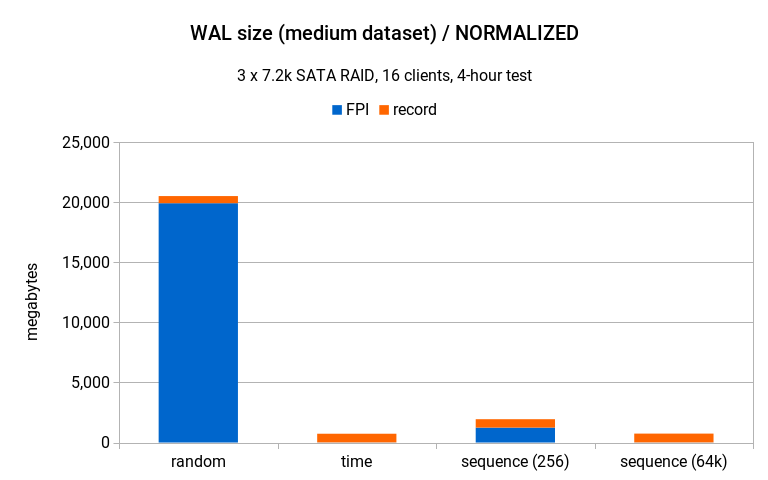
也就是说 - 差异更加显著,这很好地说明了随机 UUID 的 WAL 写入放大问题。
大型数据集
在大型数据集上,它看起来与中型数据集非常相似,尽管这次随机生成器产生的 WAL 量比序列 (256) 少。
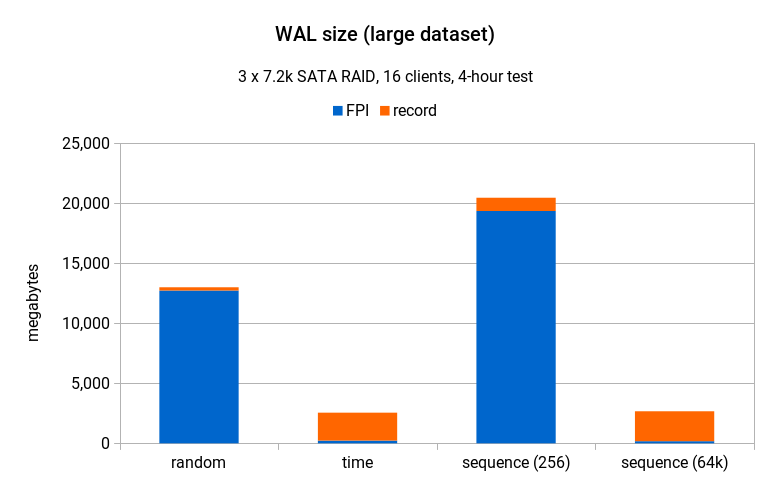
但同样,该图表忽略了不同生成器具有非常不同的吞吐量的事实(与其他两个生成器相比,随机模式仅达到了大约 20%),如果我们将其扩展到相同的吞吐量,它看起来如下所示:
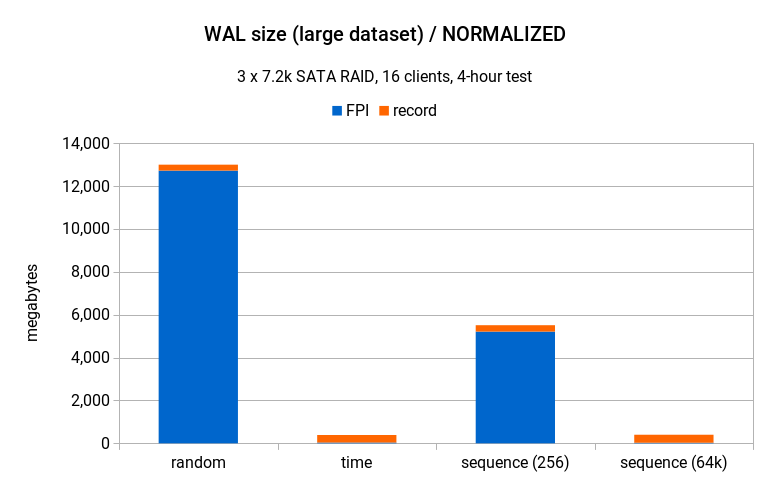
与随机生成器相比,序列 (256) 产生了更多的 WAL(20GB 对比 13GB),但为何能达到大约 3 倍的吞吐量?一个原因是 WAL 的数量在这里并不重要 – SATA 磁盘可以很好地处理顺序写入,4 小时内 20GB 几乎不算什么。更重要的是数据文件本身(尤其是索引)的写入模式,而序列 (256) 的写入模式顺序性高多了。
缓存命中率
产生的 WAL 量很好地说明了写入放大,以及对写入模式的大概影响。但是读取访问模式呢?我们可以查看的一个指标是缓存命中率。对于共享缓冲区,它看起来像这样:
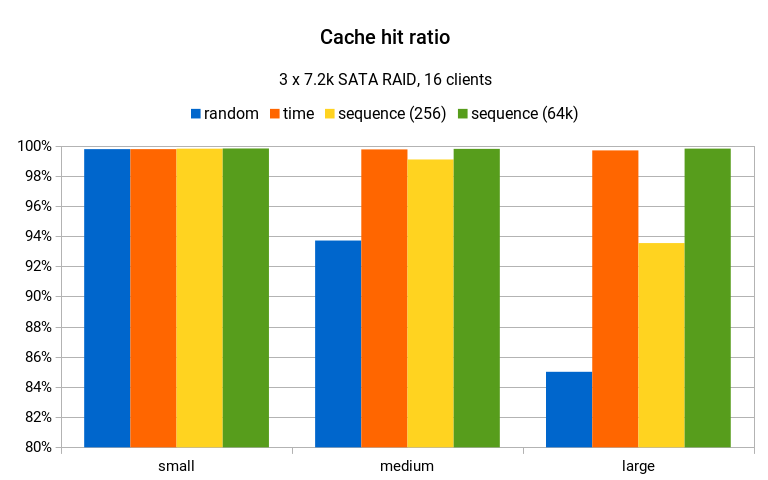
表现最佳的生成器可实现 ~99% 的缓存命中率,这非常出色。在大型数据集上,随机模式下降到只有 85% 左右,而序列 (256) 保持了大约 93% – 虽然说不上很好,但仍然比 85% 好得多。
另一个有趣的统计数据是,WAL 流中提到的不同索引块的数量。在大型数据集上,它看起来像这样:
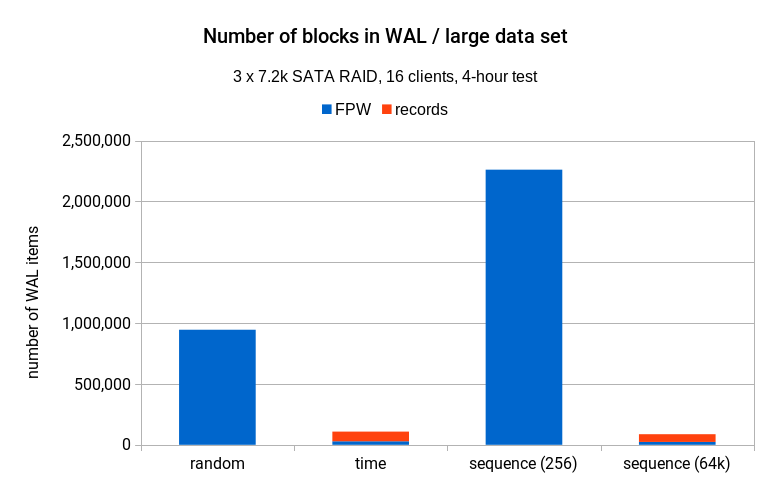
该图表可能看起来有点令人惊讶,因为序列 (256) 生成器访问的不同块数量,是随机生成器的两倍多,同时获得了 3 倍的性能。乍一看这似乎很令人惊讶,但还是由于序列 (256) 的访问模式顺序性更高。
选择参数
uuid_sequence_nextval和uuid_time_nextval函数都有参数,因此很自然地需要清楚,如何选择正确的参数值。例如,在本文介绍的测试中,block_size设置为 64k 时(与 256 相比),uuid_sequence_nextval的性能要好得多。那么为什么不总是使用 64k 呢?
答案是 - 这要看情况。64k 可能适用于较繁忙的系统,但对于其他系统,它可能太高了。此外,您需要同时选择两个参数(区块大小和区块数量)。了解几个问题 – 生成器应该多久回绕到 0?这意味着会有多少个 UUID?然后选择足够高的区块数量,将索引切成足够小的区块,并选择与所需的回绕间隔相匹配的区块大小。
总结
如测试所示,顺序 UUID 生成器显著降低了写入放大,使 I/O 模式顺序性更高,它还可以改善读取访问模式。这会帮助到您的应用吗?很难说,你得试一试。您的数据库结构可能更复杂,并且使用各种其他索引,因此从更大的角度来看,由于 UUID 导致的问题也可能可以忽略不计。