由 John Doe 九月 27, 2024
摘要:在本文中,我们将学习如何为 PostgreSQL 中的表和索引选择存储设备。
目录
介绍
尽管将来大多数数据库服务器(尤其是处理类似 OLTP 工作负载的数据库服务器),将会采用基于闪存的存储,但我们还没有做到这一点 - 闪存存储仍然比传统硬盘驱动器贵得多,因此许多系统混合使用 SSD 和 HDD 驱动器。然而,这意味着我们需要决定如何拆分数据库 – 什么数据应该放到旋转的机械盘(HDD),什么更适合使用更昂贵但在处理随机 I/O 方面更好的闪存存储。
有一些解决方案尝试通过自动使用 SSD 作为缓存,自动将活跃部分的数据保留在 SSD 上,从而在存储级别自动处理此问题。存储设备/SAN 通常在内部执行此操作,在单套硬件设备中带有大型 HDD 和小型 SSD 的混合 SATA/SAS 驱动器,当然还有直接在主机上执行此操作的解决方案,例如,Linux 中有 dm-cache,LVM 在 2014 年也获得了这样的功能(建立在 dm-cache 之上),当然 ZFS 也有 L2ARC。
但是,让我们忽略所有这些自动设置方案,假设我们有两台设备直接连接到系统:一台基于 HDD,另一台基于闪存。您应该如何拆分数据库以充分利用昂贵的闪存?一种常用的模式是按对象类型执行此操作,特别是表与索引。这通常是有道理的,但我们经常看到人们将索引放在 SSD 存储上,因为索引与随机 I/O 相关联。虽然这看起来很合理,但事实证明这与您应该做的事情恰恰相反。
进行一个基准测试
让我在同时具有 HDD 存储(由 4 个 10k SAS 驱动器构建的 RAID10)和单个 SSD 设备(Intel S3700)的系统上演示这一点。该系统有 16GB 的内存,所以让我们使用比例为 300(=4.5GB)和 3000(=45GB)的 pgbench,即一个可以轻松放入内存和多倍内存容量的 pgbench。然后,让我们将表和索引放在不同的存储系统上(通过使用表空间),并测量性能。数据库集群在硬件资源方面进行了合理配置(共享缓冲区、WAL 限制等)。WAL 放置在单独的 SSD 设备上,连接到与 SAS 驱动器共享的 RAID 控制器。
在小型(4.5GB)数据集上,结果如下所示(请注意,y 轴从 3000 tps 开始):
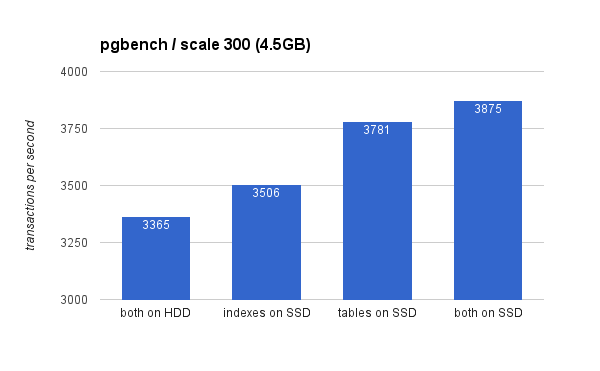
显然,与将 SSD 用于表相比,将索引放在 SSD 上的好处较低。虽然数据集很容易放入内存,但更改最终需要写入磁盘,虽然 RAID 控制器具有写入缓存,但它无法真正与闪存竞争。新的 RAID 控制器可能会性能更好一些,但新的 SSD 驱动器也会更好。
在大型数据集上,差异要显著得多(这次 y 轴从 0 开始):
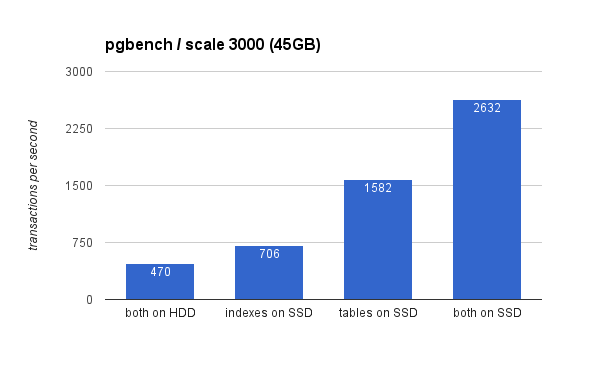
将索引放在 SSD 上可以显著提高性能(以 HDD 存储为基准,将近 50%),但将表移动到 SSD 上可以轻松获得 200% 以上的性能提升。当然,如果您将表和索引都放在 SSD 上,您将进一步提高性能,但如果您能够做到这一点,则无需担心其他情况。
为什么会出现上面的结果?
通过在 SSD 上放置表来获得更好的性能,似乎有点违反直觉,那么为什么它会像这样呢?嗯,这可能是几个因素的组合:
- 索引通常比表小得多,因此更容易放入内存
- 索引级别中的页面(在树中)通常非常热,因此保留在内存中
- 在扫描索引时,许多实际的 I/O 本质上是顺序化的(特别是对于叶子页)
这样做的结果是,针对索引的大量 I/O 要么根本没有发生(由于缓存),要么是 I/O 顺序化了。另一方面,索引是针对表的随机 I/O 的重要来源。
不过,实际情况要复杂得多…
当然,这只是一个简单的示例,例如,对于截然不同的业务负载,结论可能会有所不同。同样,由于 SSD 更昂贵,因此系统在 HDD 驱动器上的磁盘空间往往比在 SSD 驱动器上多,因此表可能无法放在 SSD 上,而索引则适合。在这些情况下,需要更复杂的安排 – 例如,不仅要考虑对象的类型,还要考虑它的使用频率(并且只将大量使用的表移动到 SSD),甚至是表的子集(例如,通过逐渐将旧数据从 SSD 移动到 HDD)。