由 John Doe 十月 17, 2024
摘要:在本文中,我们将学习如何使用 PostgreSQL 处理标签。
目录
今天,我将使用一个猫及其属性的示例数据库,来演练在 PostgreSQL 中处理标签
- 首先,我们将看一个传统的关系模型
- 其次,我们将了解如何使用整数数组来存储标签
- 最后,我们将测试文本数组,直接嵌入标签和猫的信息
关系模型中的标签
对于这些测试,我们将使用一个非常简单的cats表、相关联的实体,以及一个包含 10 个表示猫的标签的短表tags。在两个表之间,tags 和 cats 之间的关系存储在cat_tags表中。
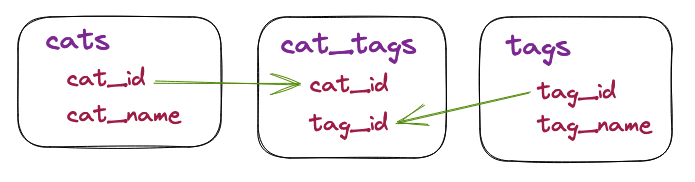
表创建 SQL
CREATE TABLE cats (
cat_id serial primary key,
cat_name text not null
);
CREATE TABLE cat_tags (
cat_id integer not null,
tag_id integer not null,
unique(cat_id, tag_id)
);
CREATE TABLE tags (
tag_id serial primary key,
tag_name text not null,
unique(tag_name)
);
我在表中为cats填充了超过 1.7M 个条目,为tags填充了 10 个条目,为 cat/tag 的关系填充了 4.7M 个条目。
数据生成 SQL
– 随机生成猫的名字
INSERT INTO cats (cat_name)
WITH
hon AS (
SELECT *
FROM unnest(ARRAY['mr', 'ms', 'miss', 'doctor', 'frau', 'fraulein', 'missus', 'governer']) WITH ORDINALITY AS hon(n, i)
),
fn AS (
SELECT *
FROM unnest(ARRAY['flopsy', 'mopsey', 'whisper', 'fluffer', 'tigger', 'softly']) WITH ORDINALITY AS fn(n, i)
),
mn AS (
SELECT *
FROM unnest(ARRAY['biggles', 'wiggly', 'mossturn', 'leaflittle', 'flower', 'nonsuch']) WITH ORDINALITY AS mn(n, i)
),
ln AS (
SELECT *
FROM unnest(ARRAY['smithe-higgens', 'maclarter', 'ipswich', 'essex-howe', 'glumfort', 'pigeod']) WITH ORDINALITY AS ln(n, i)
)
SELECT initcap(concat_ws(' ', hon.n, fn.n, mn.n, ln.n)) AS name
FROM hon, fn, mn, ln, generate_series(1,5)
ORDER BY random();
– 填入标签名称
INSERT INTO tags (tag_name) VALUES
('soft'), ('cuddly'), ('brown'), ('red'), ('scratches'), ('hisses'), ('friendly'), ('aloof'), ('hungry'), ('birder'), ('mouser');
– 生成随机标签。每只猫都有 25% 的概率获得每个标签。
INSERT INTO cat_tags
WITH tag_ids AS (
SELECT DISTINCT tag_id FROM tags
),
tag_count AS (
SELECT Count(*) AS c FROM tags
)
SELECT cat_id, tag_id
FROM cats, tag_ids, tag_count
WHERE random() < 0.25;
– 创建索引
CREATE INDEX cat_tags_x ON cat_tags (tag_id);
关系模型总共需要 2424KB 的存储空间,用于cats、tags和标签的关系。
SELECT pg_size_pretty(
pg_total_relation_size('cats') +
pg_total_relation_size('cat_tags') +
pg_total_relation_size('tags'));
关系查询的性能
我们将要关注性能,因此请设置好计时,以查看事情需要多长时间。在每条语句运行后,系统还将提供耗时的输出。
\timing
有两个标准方向的标签查询:
- “这只猫有什么标签?”
- “哪些猫有这个特定的标签或一组标签?”
这只猫有什么标签?
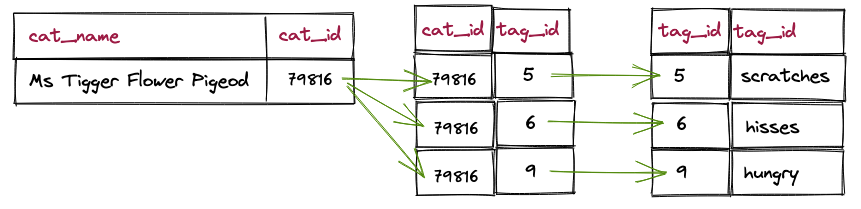
查询很简单,性能非常好(不到 1 毫秒)。
SELECT tag_name
FROM tags
JOIN cat_tags USING (tag_id)
WHERE cat_id = 444;
哪些猫有这个标签?
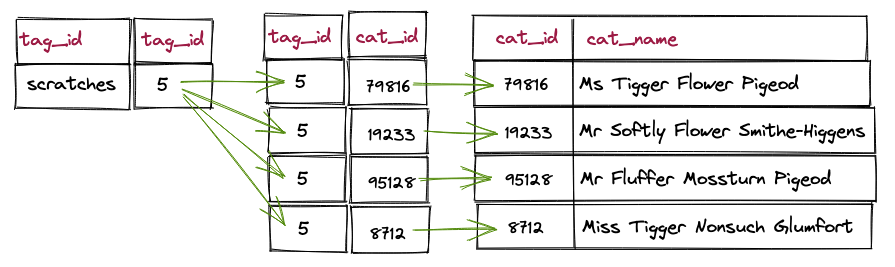
查询仍然很简单,并且相对满足筛选条件的记录数来说,性能表现也正常。
SELECT Count(*)
FROM cats
JOIN cat_tags a ON (cats.cat_id = a.cat_id)
JOIN tags ta ON (a.tag_id = ta.tag_id)
WHERE ta.tag_name = 'brown';
哪些猫有这两个标签呢?
这就是关系模型开始偏离轨道的地方,因为查找只具有两个特定标签的记录涉及相当复杂的 SQL。
SELECT Count(*)
FROM cats
JOIN cat_tags a ON (cats.cat_id = a.cat_id)
JOIN cat_tags b ON (a.cat_id = b.cat_id)
JOIN tags ta ON (a.tag_id = ta.tag_id)
JOIN tags tb ON (b.tag_id = tb.tag_id)
WHERE ta.tag_name = 'brown' AND tb.tag_name = 'aloof';
此查询大约需要 >1 秒,才能找到既是 “brown” 又是 “aloof” 的猫。
哪些猫有这三个标签?
为了让您看懂查询模式,这里是三个标签的版本。
SELECT Count(*)
FROM cats
JOIN cat_tags a ON (cats.cat_id = a.cat_id)
JOIN cat_tags b ON (a.cat_id = b.cat_id)
JOIN cat_tags c ON (b.cat_id = c.cat_id)
JOIN tags ta ON (a.tag_id = ta.tag_id)
JOIN tags tb ON (b.tag_id = tb.tag_id)
JOIN tags tc ON (c.tag_id = tc.tag_id)
WHERE ta.tag_name = 'brown'AND tb.tag_name = 'aloof'AND tc.tag_name = 'red';
此时,结果集中记录数的减少,正在抵消多重连接日益增长的复杂性,查询时间仅增加到 >2 秒。
但想象一下对 5 个、6 个或 7 个标签执行此操作呢?
整数数组模型中的标签
如果我们更改模型,不使用相关表对猫和标签的关系进行建模,而是使用整数数组对其进行建模,情况会怎样?
CREATE TABLE cats_array (
cat_id serial primary key,
cat_name text not null,
cat_tags integer[]
);
现在,我们的模型只有两个表,cats_array和tags。
我们可以从关系数据中填充基于数组的表,以便我们可以比较模型之间的结果。
数据生成 SQL
INSERT INTO cats_array
SELECT cat_id, cat_name, array_agg(tag_id) AS cat_tags
FROM cats
JOIN cat_tags USING (cat_id)
GROUP BY cat_id, cat_name;
使用这个新的数据模型,所需表的大小减少了,我们只使用了 1040KB。
SELECT pg_size_pretty(
pg_total_relation_size('cats_array') +
pg_total_relation_size('tags'));
加载数据后,我们需要最重要的部分 – 在cat_tags整数数组上的索引。
CREATE INDEX cats_array_x ON cats_array USING GIN (cat_tags);
这个 GIN 索引非常适合为集合(如我们的数组)建立索引,其中集合中有固定和有限数量的值(如我们的 10 个标签)。虽然 PostgreSQL 附带了 intarray 扩展,但内核对数组和数组索引的支持已经赶上了扩展,并使大部分扩展变得多余。
和之前一样,我们将测试常见的基于标签的使用案例。
这只猫有什么标签?
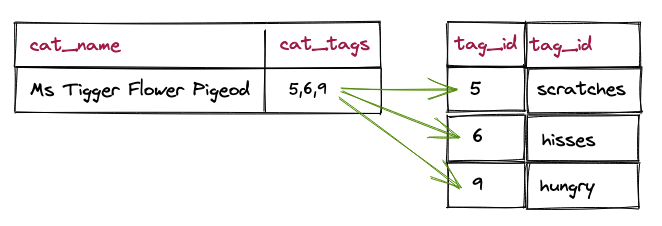
查询就不那么美观了!首先,我们必须在cat_tags中查找tag_id值,并使用unnest()将它们扩展为一个关系。然后,我们准备将该关系连接到tags表,以查找对应于tag_id的tag_name。
SELECT c.cat_id, c.cat_name, t.tag_name
FROM cats_array c
CROSS JOIN unnest(cat_tags) AS tag_id
JOIN tags t USING (tag_id)
WHERE cat_id = 779;
查询命中了cats主键索引,并在 100 毫秒范围内返回了。性能很出色!
哪些猫有这些(三个)标签?
这是让我们的关系模型感到困惑的查询。让我们直接跳到最难的情况,尝试找到所有 “red”、“brown” 和 “aloof” 的猫。
WITH tags AS MATERIALIZED (
SELECT array_agg(tag_id) AS tag_ids
FROM tags
WHERE tag_name IN ('red', 'brown', 'aloof')
)
SELECT Count(*)
FROM cats_array
CROSS JOIN tags
WHERE cat_tags @> tags.tag_ids;
首先,我们必须访问tags表,构建一个与我们的标签相对应的tag_id条目数组。然后我们可以使用 PostgreSQL 数组运算符 @>来测试,看看哪些猫的cat_tags数组包含了查询的数组。
查询命中了cat_tags GIN 索引,并在大约 200 毫秒内返回猫的计数。这比关系模型上的相同查询快 7 倍左右!
文本数组模型中的标签
因此,如果将数据从cats -> cat_tags -> tags模型,部分地非规范化到cats -> tags模型,会让查询变得更快。如果我们一直走到最简单的模型 – 仅cats呢?
CREATE TABLE cats_array_text (
cat_id serial primary key,
cat_name text not null,
cat_tags text[] not null
);
同样,我们可以直接从关系模型填充这个新模型。
数据生成 SQL
INSERT INTO cats_array_text
SELECT cat_id, cat_name, array_agg(tag_name) AS cat_tags
FROM cats
JOIN cat_tags USING (cat_id)
JOIN tags USING (tag_id)
GROUP BY cat_id, cat_name;
结果是 1224KB,比整数数组的版本略大。
SELECT pg_size_pretty(
pg_total_relation_size('cats_array_text') +
pg_total_relation_size('tags'));
现在,每只猫在记录中都有标签名称了。
这只猫有什么标签?
由于只有一个包含所有数据的表,因此要找到猫的标签非常简单。
SELECT cat_name, cat_tags
FROM cats_array_text
WHERE cat_id = 888;
哪些猫有这些(三个)标签?
再一次,为了获得良好的性能,我们需要在将要搜索的数组上有一个 GIN 索引。
CREATE INDEX cats_array_text_x ON cats_array_text USING GIN (cat_tags);
查找出是 “red”、“brown” 和 “aloof” 的猫的查询也非常简单。
SELECT Count(*)
FROM cats_array_text
WHERE cat_tags @> ARRAY['red', 'brown', 'aloof'];
此查询花费的时间与基于整数数组的查询(120ms)大致相同。
利弊
那么,基于数组的模型是 PostgreSQL 中面向标签的查询模式的终极方案吗?从好的方面来说,数组模型是:
- 查询速度更快;
- 存储空间更小;
- 查询更简单!
这些都是非常引人注目的正向因素!
但是,在使用这些模型时,需要记住一些注意事项:
-
对于文本数组模型,没有通用的地方来查找所有标签。对于所有标签的列表,您必须扫描整个
cats表。 -
对于整数数组模型,无法创建一个简单的约束,来保证
cat_tags整数数组中使用的整数存在于tags表中。您可以使用一个TRIGGER,但它不如关系的外键约束干净。 -
对于这两个数组模型,当必须对标签使用
unnest()才能使用关系查询时,SQL 可能会变得有点粗糙。