八月 26, 2024
摘要:在本教程中,您将了解顺序扫描的内部原理。
目录
在每个数据库产品中,顺序扫描或全表扫描通常都会消耗资源,因此几乎所有开发人员和 DBA 都将此类扫描视为性能杀手。一般来说,这是一种错误的看法或有偏见的观点。在许多情况下,顺序扫描被证明可以提高性能。然而,由于缺乏认识,许多专家将顺序扫描妖魔化,并倾向于在查询执行过程中消除它们。本文重点介绍这部分,并试图阐明顺序扫描的内部原理。
什么是顺序扫描?
这是一种从表中访问数据的方法,它会扫描表中的每条记录,以查看它是否满足所需的搜索条件。从数据库访问数据时,需要确定哪些记录满足 WHERE 子句过滤条件。为了完成同样的操作,数据库产品有时需要扫描表中的所有记录,并将匹配的记录放在单独的部分中以供进一步操作。
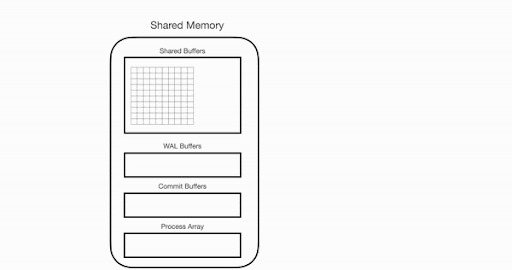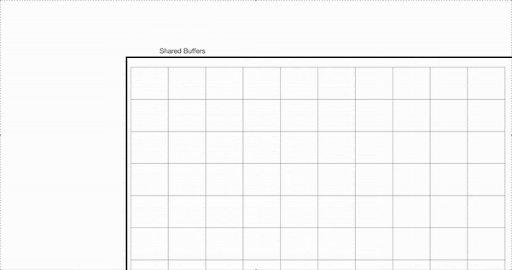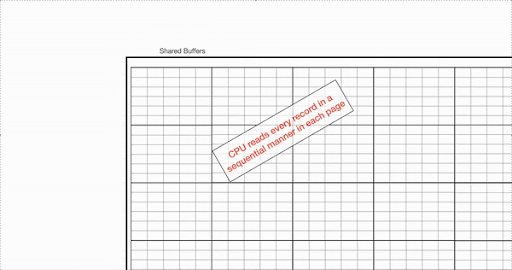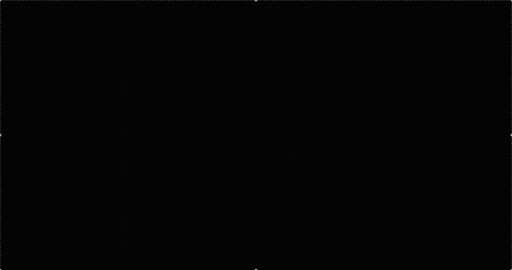
它是按页面的顺序进行扫描的。表中的每一页都在共享内存的 “共享缓冲区” 中进行扫描,然后将结果集放入用户区域(工作内存),以进行进一步的操作,例如连接、排序等。
过程
顺序扫描分为两个阶段:
- 复制页面到内存中
- 从内存页面获取数据
复制页面到内存中
在每个数据库中,在文件系统上存储数据时,它必须遵循操作系统和数据库本身的标准。在磁盘上,数据存储在大小均匀的页面中。所以,为了读取数据,首先,数据库需要读取块,这些块也称为页。对于 PostgreSQL,页面大小为 8kB。每当 PostgreSQL 需要从数据库中读取数据时,数据库页面将被加载到内存区域的特定部分,该区域称为共享缓冲区。
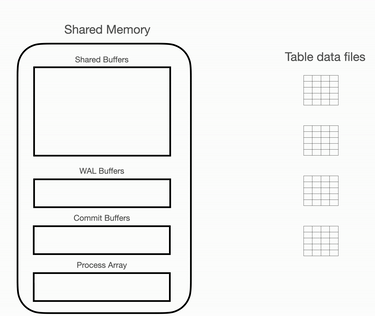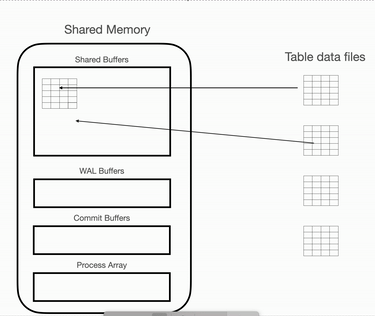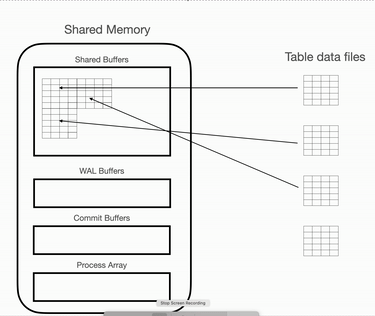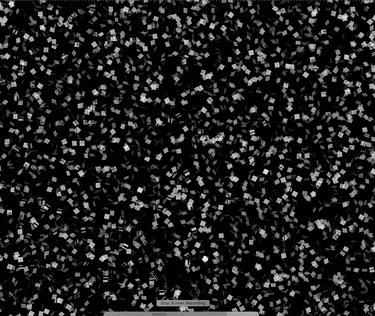
从内存页面获取数据
在共享缓冲区加载了所需的页面后,PostgreSQL 会扫描内存中的这些块,并从页面中提取行。在此操作期间,将读取每个页面,并将所有记录与过滤条件进行匹配和比较。
这是需要 CPU 运算的操作。在此操作中,CPU 将应用逻辑,从共享缓冲区读取页面,并从内存页面获取行。在此操作期间,处理器将不断从一个页面迭代到另一个页面,从一条记录迭代到另一条记录。这将一直持续到读取最后一条记录。因此,当有顺序扫描正在进行时,处理器会保持忙碌状态。
成本计算
如过程部分所述,完整的操作分两个阶段进行。这两项操作的总成本是单独计算的,并以两者的总和进行呈现。第一个操作的成本称为 IO 成本,它估计执行 IO 所需的工作量。另一个成本是 CPU 成本。
磁盘运行成本
在顺序扫描的情况下,每个元组都要从磁盘读取。在每个磁盘上,数据页都按顺序存储。此外,它们的访问方式相同。因此,磁盘必须按顺序读取块,这也称为顺序读取。在 PostgreSQL 中,我们可以通过设置 PG 参数 seq_page_cost,来设置获取一个页面的估计成本。
disk_run_cost = the number of pages * seq_page_cost
(一个表中的页数存储在 pg_class 的 relpages 列中。)
CPU 运行成本
当页面被加载到内存(共享缓冲区)中时,它们仍然只能以 PG 块的形式来访问。但是,它们只能由操作系统读取,并且在页面内的读取数据收集完之前没有任何用处。CPU 的工作从这里开始!CPU 必须识别页面中的元组,并提取它们以执行各种操作。在 PostgreSQL 中,我们可以使用 cpu_tuple_cost 参数,设置获取一条记录所需的估计成本,然后将其乘以表中的总行数,我们可以得到 cpu_run_cost。
cpu_run_cost = Total number of records * cpu_tuple_cost
(一个表中的记录数存储在 pg_class 的 reltuples 列中。)
执行顺序扫描所需的总成本是 CPU 运行成本和磁盘运行成本之和。
total_cost = disk_run_cost + cpu_run_cost
在这里,我们举一个示例来计算该值,并使用 EXPLAIN ANALYZE 对其进行验证。下面的查询显示了必要的详细信息以及统计信息。
SELECT relation.no_of_pages AS "No. of Pages",
seq_page_cost.value AS "seq_page_cost",
relation.no_of_rows AS "No. of records",
cpu_tuple_cost.value AS "cpu_tuple_cost",
(relation.no_of_pages * seq_page_cost.value) AS "Disk run cost",
(relation.no_of_rows * cpu_tuple_cost.value) AS "CPU run cost",
(relation.no_of_pages * seq_page_cost.value + relation.no_of_rows * cpu_tuple_cost.value) AS "Total cost"
FROM
(SELECT setting::float value FROM pg_settings WHERE name = 'cpu_tuple_cost') cpu_tuple_cost,
(SELECT setting::float value FROM pg_settings WHERE name = 'seq_page_cost') seq_page_cost,
(SELECT reltuples::int no_of_rows, relpages::int no_of_pages FROM pg_class WHERE relname = 'sequential_scan_test_tbl') relation;
No. of Pages | seq_page_cost | No. of records | cpu_tuple_cost | Disk run cost | CPU run cost | Total cost
--------------+---------------+----------------+----------------+---------------+--------------+------------
14803 | 1 | 126728 | 0.01 | 14803 | 1267.28 | 16070.28
(1 row)
下面的 EXPLAIN ANALYZE 命令显示了查询产生的成本。我们可以看到它与上面查询中的 “Total cost” 相同。
EXPLAIN ANALYZE SELECT * FROM sequential_scan_test_tbl;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on sequential_scan_test_tbl (cost=0.00..16070.28 rows=126728 width=1438) (actual time=6.202..114.818 rows=126728 loops=1)
Planning Time: 0.330 ms
Execution Time: 120.151 ms
(3 rows)
容易发生顺序扫描的情况
缺失索引
在返回相对较小数据集的任何查询中,索引都会加快数据检索速度。索引存储与特定值关联的 OID,因此在查询表数据时,它会尝试查看与 WHERE 子句中提到的列/表达式关联的索引。如果 WHERE 子句中的列没有索引,则执行器无法获取记录的详细信息,因此顺序扫描变得不可避免。
过时的统计信息
在 PostgreSQL 中,采用了一种基于成本的优化方法,以选择出最有效的执行计划;此方法严格基于表的统计信息。使用 ANALYZE 方法,其中优化引擎根据可用的统计数据来计算不同操作的成本。比较所有计划的成本,值最低的一方胜出,执行引擎会使用成本最低的计划。例如,如果顺序扫描的成本为 3000,索引扫描的成本为 150,则选择索引扫描。如果统计信息不经常更新,可能会导致执行计划不佳,从而发生顺序扫描。
大型结果集
从以上两点中可以清楚地看出,最新的统计信息和适当的索引对于避免顺序扫描很有用。但是,在某些情况下,尽管满足上述两个要求,但顺序访问数据仍然会发生。发生这种情况是因为,查询需要获取来自表的巨大数据集。在这种情况下,使用索引会产生开销,并导致执行延迟。
结论
顺序扫描会遍历一个表中的所有记录,这是一个两阶段操作,包含复制块到共享内存中和从块中读取数据。顺序扫描可能是由于统计信息不正确或缺少索引而发生的;但是,返回大量数据时是一种例外。