九月 24, 2024
摘要:在本教程中,您将了解 PostgreSQL 中全页写 full_page_writes 的影响。
目录
介绍
在调整postgresql.conf时,您可能已经注意到有一个名为full_page_writes的选项。选项旁边的注释说明了部分页面写入的影响,人们通常会将其设置为on – 这是一个好的实践,在本文后面将会解释。但是,了解全页写的作用非常有用,因为它可能会对性能有非常大的影响。
本文不会指导您如何调整服务器。实际上,您可以调整的内容并不多,但这里将向您展示一些应用程序层面的决策(例如数据类型的选择)如何会与全页写相互作用。
部分写/页面损坏
那么全页写是干什么的呢?正如postgresql.conf中的注释所说,这是一种从部分页面写入的错误中恢复的方法 – PostgreSQL 使用 8kB 页面(默认情况下),但存储栈中的其他部分使用不同的块大小。Linux 文件系统通常使用 4kB 页面(可以使用较小的页面,但在 x86 上最大为 4kB),在硬件层面,旧的驱动器使用 512B 扇区,而新设备通常以较大的块(通常为 4kB 甚至 8kB)写入数据。
因此,当 PostgreSQL 写入 8kB 页面时,存储栈中的其他层可能会将其分成更小的块,单独管理。这带来了有关写入原子性的问题。8kB 的 PostgreSQL 页面可以拆分为两个 4kB 的文件系统页面,然后拆分为 512B 扇区。现在,如果服务器崩溃(电源故障、内核错误等),会怎么样?
即使服务器采用了专为处理此类故障而设计的存储系统(带电容器的 SSD、带电池的 RAID 控制器等),内核也已经将数据拆分为 4kB 的页面。因此,数据库可能写入了 8kB 的数据页,但其中只有一部分在崩溃之前进入了磁盘。
此时,您现在可能在想,这正是我们拥有事务日志(WAL)的原因,的确如此!因此,在启动服务器后,数据库将读取 WAL(自上次完成的检查点以来),并重新应用更改以确保数据文件完整。过程相当简单。
但是有一个问题 – 恢复不会盲目地应用更改,它通常需要读取数据页等。它会假定页面尚未以某种方式出错,比如由于部分写入。这似乎有点自相矛盾,因为为了修复数据损坏,我们假定了没有数据损坏。
全页写是解决这个难题的一种方式:在一次检查点之后第一次修改页面时,整个页面都会写入 WAL。这保证了在恢复过程中,修改页面的第一条 WAL 记录包含整个页面,无需从数据文件中读取可能损坏的页面。
写入放大
当然,这样做的负面后果是 WAL 日志量的增加 – 更改 8kB 页面上的单个字节会将整个页面记录到 WAL 中。全页写仅发生在检查点之后的第一次写入时,因此降低检查点的频率是改善这种情况的一种方法 – 通常,在检查点之后会出现短暂的“大量”全页写入,接着是相对较少的全页写入,直到检查点结束。
UUID 对比 bigserial 键
但是,在应用程序层面做出的设计决策,会存在一些意想不到的作用。假设我们有一个带有主键的简单表,主键类型为BIGSERIAL或UUID,并将数据插入其中。生成的 WAL 日志量会有所不同吗(假设我们插入相同数量的行)?
预期两种情况产生大致相同数量的 WAL 日志,似乎是合理的,但是如下图所示,在实践中存在巨大的差异。
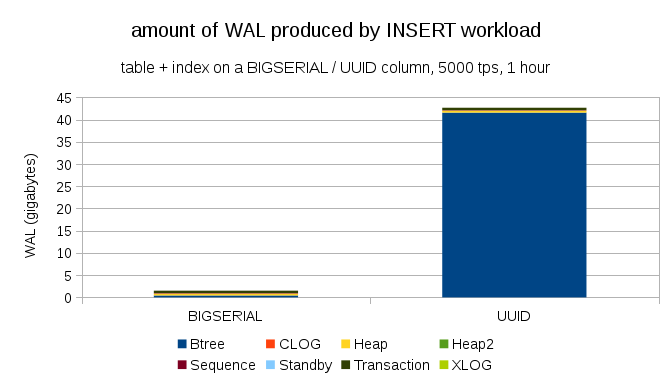
这显示了在 1 小时基准测试期间产生的 WAL 日志量,测试限制为每秒 5000 次插入。使用BIGSERIAL主键时,生成了 ~2GB 的 WAL,而使用UUID主键时,生成了超过 40GB 的 WAL。这是相当显著的差异,很明显,大多数 WAL 日志都与支持主键的索引有关。让我们看看 WAL 记录的类型。
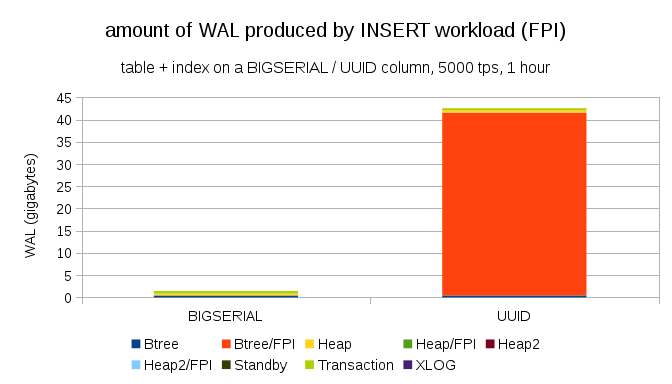
显然,绝大多数 WAL 记录是全页镜像(FPI),即全页写入的结果。但为什么会这样呢?
当然,这是由于UUID固有的随机性。使用BIGSERIAL的键值是连续的,因此可以插入到 B 树索引中的相同叶子页面。由于只有对页面的第一次修改会触发全页写入,因此只有一小部分 WAL 记录是 FPI。UUID的情况完全不同,因为:这些值根本不是连续的,事实上,每个插入都可能触及全新的索引叶子页面(假设索引足够大)。
数据库能做的不多 – 业务负载本质上是随机的,会触发许多全页写入。
当然,即使使用BIGSERIAL类型的主键,获得类似的写入放大也不难。它只需要不同的工作负载 – 例如,使用UPDATE业务负载,随机更新在表中均匀分布的记录,图表如下所示:
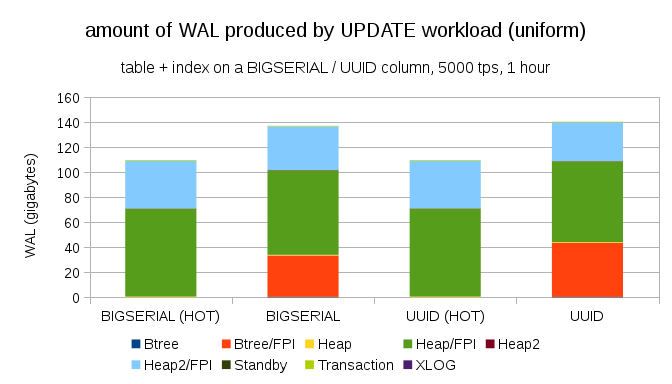
突然之间,数据类型之间的差异消失了 – 两种情况下的访问都是随机的,导致产生的 WAL 日志量几乎完全相同。另一个区别是大多数 WAL 记录与“堆表”相关联,即表,而不是索引。“HOT” 时的情况旨在进行 HOT UPDATE 优化(即无需触及索引即可更新),这几乎消除了所有与索引相关的 WAL 流量。
但您可能会争辩说,大多数应用程序不会更新整个数据集。通常,只有一小部分数据是“活跃的” – 人们只会访问过去几天在论坛上的帖子、电子商店中未处理的订单等。这对结果有什么影响呢?
值得庆幸的是,pgbench 支持非均匀分布,例如,采用指数分布在 ~25% 的时间内修改 1% 的数据子集,图表如下所示:
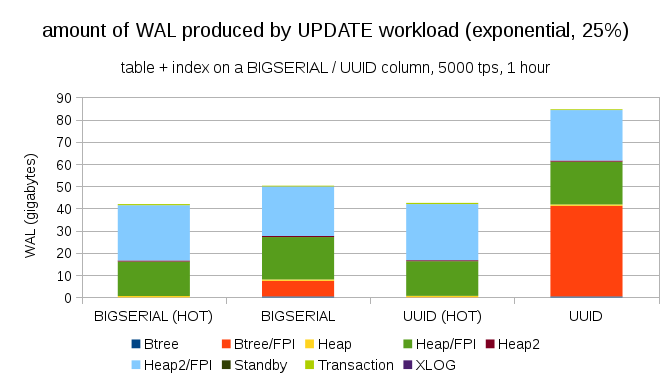
在让分布更加偏斜之后,在 ~75% 的时间内修改 1% 子集:
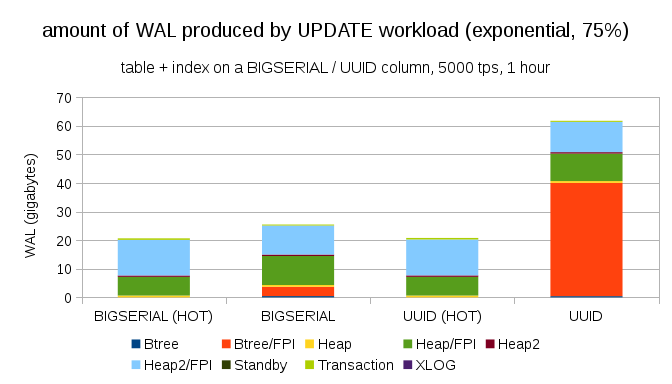
这再次表明了数据类型的选择可能会产生多大的差异,以及针对 HOT 更新进行优化的重要性。
8KB 和 4KB 页面
一个有趣的问题是,在 PostgreSQL 中使用较小的页面,可以节省多少 WAL 流量(这需要自定义编译软件包)。在最好的情况下,它可能会节省高达 50% 的 WAL,这要归功于仅记录 4kB 而不是 8kB 的页面。对于具有均匀分布的 UPDATE 的业务负载,它看起来像这样:
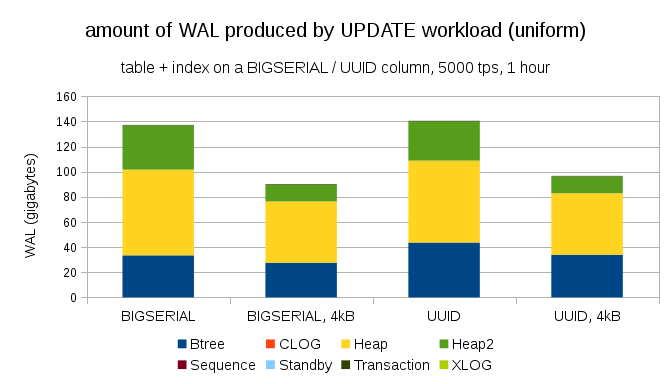
所以节省并不完全是 50%,但从 ~140GB 减少到 ~90GB 仍然相当显著。
我们还需要全页写吗?
在解释了部分写入的危险之后,这似乎很荒谬,但至少在某些情况下,禁用全页写入可能也是一个可行的选择。
首先,我想知道现代的 Linux 文件系统是否仍然容易受到部分写入的影响?该参数是在 2005 年发布的 PostgreSQL 8.1 中引入的,因此,在此后文件系统进行了许多改进后,这可能不再是一个问题。对于任意业务负载来说可能并不普遍,但也许假设一些额外的条件(例如在 PostgreSQL 中使用 4KB 页面大小)就足够了?此外,PostgreSQL 永远不会只覆盖 8KB 页面的一部分 - 整个页面总是会一次被写出。即使它仍然是一个问题,数据校验和也可能有足够的保护(它不会解决问题,但至少会让你知道有一个损坏的页面)。
其次,现在许多系统都依赖于流复制的副本 – 在出现硬件问题后,系统不会等待服务器重启(这可能需要相当长的时间),然后花更多时间执行恢复,而是会简单地切换到热备。如果故障的主数据库会被删除(然后从新的主数据库克隆),则部分写入就不是问题了。
但是,如果我们开始推荐这样的实践,那么 DBA 在承担事故责任时,很可能会疑惑:自己只是在系统上设置了full_page_writes = off,却莫名奇妙地出现了数据损坏!
总结
对于全页写入的优化,您并没有太多直接可以操作的空间。对于大多数业务负载,大多数全页写入发生在检查点之后,然后会消失,直到下一个检查点。因此,调整检查点以让它不要太频繁地发生是很重要的。
一些应用程序层面的决策,可能会增加对表和索引的写入的随机性 – 例如 UUID 值本质上是随机的,即使是简单的 INSERT 业务负载也会变成随机索引更新。示例中使用的业务模型相当简单 – 实际情况中,还会有二级索引、外键等。但是,在内部使用 bigserial 类型的主键(并将 UUID 保留为替代键)至少能减少写入放大。