八月 20, 2024
摘要:在本教程中,您将学习 PostgreSQL 中索引的负面影响和成本。
目录
介绍
在 SQL 性能调优方面,索引通常被认为是灵丹妙药,PostgreSQL 支持不同类型的索引,以满足不同的场景。人们发现,创建越来越多的索引的冲动,在许多系统中造成了严重的损害。很多时候,为了整体系统的效益,在考虑任何新的索引之前,我们应该首先删除索引。惊讶吗?了解索引的后果和开销,有助于做出明智的决策,并可能使系统免于许多潜在问题。
在非常基本的层面上,我们应该记住,索引不是免费的。它在带来好处的同时,也伴随着性能和资源消耗方面的成本。以下是过度使用索引可能导致的十种问题/开销的列表。这篇文章是关于 PostgreSQL 的,但大多数问题也适用于其他数据库系统。
过多的索引会损害 PostgreSQL 性能的 10 种方式
索引会拖慢事务
添加索引后,我们可能会看到 SELECT 语句的性能有所提高。但是,我们不应忘记,在提高性能的同时,也会伴随着同一个表上的事务的成本增加。从概念上讲,表上的每次 DML 都需要更新表的所有索引。尽管有很多优化措施来减少写入放大,但这是一个相当大的开销。
例如,假设一个表上有五个索引;表中的每次 INSERT 都需要往这五个索引 INSERT 索引记录。从逻辑上讲,也将更新五个索引页。因此,实际上,开销是 5 倍。
内存使用情况
索引页必须要在内存中,无论是否有任何查询会使用它们,因为它们需要被事务进行更新。实际上,可用于表页的内存会减少。索引越多,有效的缓存对内存的要求就越高。如果我们不增加可用内存,这就会开始损害系统的整体性能。
随机写: 更新索引的成本更高
与 INSERT 新记录到表中不同,行不太可能插入到同一页面中。众所周知,像 B 树索引这样的索引会引发更多的随机写。
索引比表需要更多的缓存
由于随机的写和读,索引需要更多页面才能包含在缓存中。索引对缓存的要求通常远高于关联的表。
WAL 生成
除了表更新的 WAL 记录外,还会有索引的 WAL 记录。这有助于崩溃恢复和复制。如果您正在使用任何等待事件分析工具/脚本(如 pg_gather),则 WAL 生成的开销将清晰可见。实际的影响取决于索引类型。
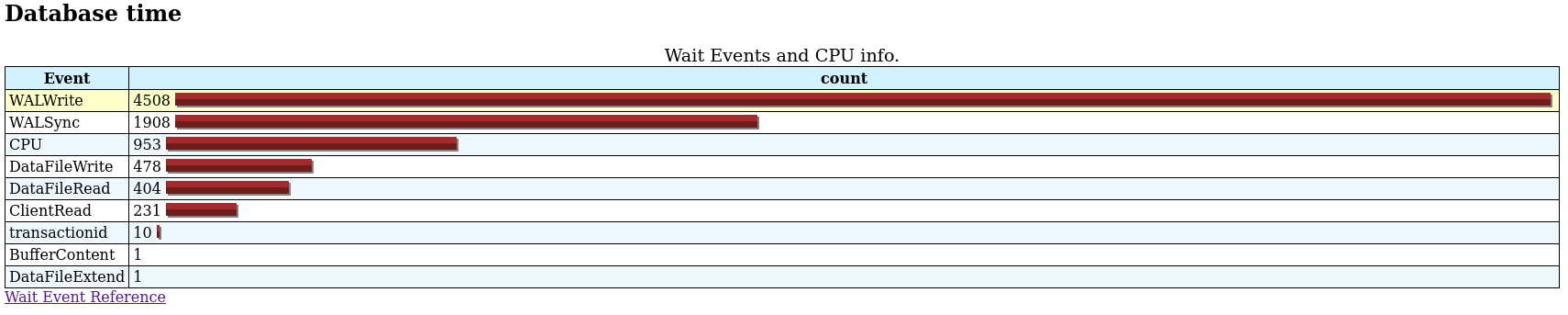
这是一个综合性测试用例,但如果与 WAL 相关的等待事件显示为任何排名靠前的等待事件,那么这是一个事务系统需要关注的问题,我们应该采取一切措施来解决这个问题。
越来越多的 I/O
不仅会生成 WAL 记录;我们也会有更多页面被弄脏。当索引页被弄脏时,必须将它们写回到文件,从而再次引发更多的 I/O - “DataFileWrite” 等待事件,如前一个屏幕截图所示。
另一个副作用是索引会增加活跃数据集的总大小。我所说的“活跃数据集”是指经常查询和使用的表和索引。随着活跃数据集大小的增加,缓存的效率会越来越低。效率较低的缓存会引发更多的数据文件读取,因此读取 I/O 会增加。这是为特定查询从存储中读取其他索引页所需的 I/O 以外的额外代价。
同样,另一个主要包含 SELECT 查询的系统,它的 pg_gather 报告也显示了这个问题。正如活跃数据集上升所体现的,PostgreSQL 别无选择,只能从存储中取出页面。

持续时间越长,“DataFileRead” 百分比越大,则表明活跃数据集要大得多,这是不可缓存的。
对 VACUUM/AUTOVACUUM 的影响
如前面几点所述,开销不仅仅是插入或更新索引页。维护它也会产生开销,因为索引还需要清理旧的元组引用。
我见过这样的情况:由于表的大小,最重要的是,由于表上的索引数量过多,单个表上的 autovacuum worker 运行时间很长。事实上,很多用户看到过他们的 autovacuum worker “卡住”了几个小时,在较长的时间内没有显示出任何进展。发生这种情况的原因是 autovacuum 的索引清理是 autovacuum 中的隐藏阶段,并且在 pg_stat_progress_vacuum 这样的视图中不可见,除非该 VACUUM 阶段被指明为正在清理索引。
随着时间的推移,索引可能会变得臃肿,并且访问效率降低。许多系统中可能需要定期维护 索引(REINDEX)。
调优时的隧道视野
隧道视野是视野的丧失。用户可能正在专注于特定的 SQL 语句,试图进行“调优”,并决定是否创建索引。通过创建用于优化查询的索引,我们将更多的系统资源转移到该查询。然后,它可能会通过损害其他方面,来为该特定语句提供更多性能。
但是,随着我们不断创建越来越多的索引,来调优其他查询,资源将再次转向其他查询。这会导致这样一种情况,即调优每个查询的努力会损害所有其他查询。最终,每个查询都会受到伤害,在这场资源争夺的战争中剩下的只有失败者。尝试调优的人应该考虑系统的每个部分如何共存(最大化业务价值),而不是特定查询的性能绝对最大化。
更大的存储需求
几乎每天,我都会看到索引比表占用更多存储空间的情况。
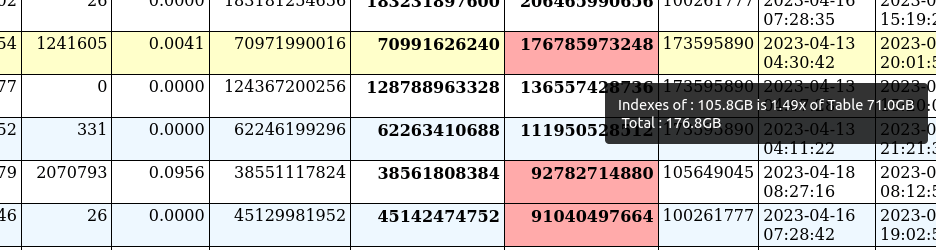
对于那些有更多钱花在存储上的人来说,这听起来可能太傻了,但我们应该记住,这会产生连锁反应。数据库总大小增长到实际数据量的多倍。因此,很明显,备份需要更多的时间、存储和网络资源,然后同样的备份会给主机带来更多的负载。这也将增加还原备份和恢复备份的时间。更大的数据库会影响很多事情,包括需要更多时间来构建备用实例。
索引更容易损坏
这不只是在谈论那些很少发生的与索引相关的软件错误,例如 PostgreSQL 14 存在的索引损坏,或由于 glibc 排序规则更改导致的索引损坏,这些错误会时不时地出现,甚至在今天也会影响许多环境。随着索引数量的增加,发生索引损坏的概率也会增加。
我们该怎么办?
在考虑创建新的索引前,应该注意考虑一些关键问题:是否必须拥有此索引,还是有必要以引入更多索引为代价来加快查询速度?有没有办法重写查询,以获得更好的性能?抛开微小的收益,没有这个索引的系统能运行吗?
现有的索引也需要在一段时间内进行严格审查。应考虑删除所有未使用的索引(pg_stat_user_indexes 中 idx_scan 为零的索引)。像 pgexperts 这样的脚本可以帮助进行更多分析。
即将推出的 PostgreSQL 16,在 pg_stat_user_indexes / pg_stat_all_indexes 中增加了一列,名称为 last_idx_scan,它可以告诉我们最后一次使用索引的时间(timestamp)。这将有助于我们充分了解系统中的所有索引。
总结
简单作个总结:**索引并不便宜。它是有代价的,而且代价可能是多方面的。索引并不总是好的,顺序扫描也并不总是坏的。**建议您,避免在改进单个查询的第一步就去创建索引,因为这是一个滑坡。自上而下的系统调优方法,从调优主机、操作系统、PostgreSQL 参数、数据架构等开始,会产生更好的结果。在创建索引之前,一次客观的“成本效益分析”是很重要的。