八月 29, 2024
摘要:在本教程中,您将学习如何在 PostgreSQL 中利用只用索引的扫描。
目录
介绍
在文章索引扫描类型:位图、索引和只用索引中,我们回顾了 PostgreSQL 使用索引尽快检索数据的三种方式。在同一篇文章中,我们看到了最快、最有效的方法是 Index-Only Scan,因为它通过避免对堆(表页)的第二次读取,并仅从对索引的单次读取,获取查询请求的所有数据来节省时间。
根据定义,利用只用索引的扫描的查询,表现比其他方法更快,但在关联到事务量时,其优势更加明显。您的系统产生的查询工作负载越多,在进行只用索引的扫描时获得的好处就越多。
业务负载测试
为了更清楚地看到这一点,我们继续使用文章中的同一个表,这次有 500K 行。我们将执行以下查询:
SELECT age, register_date, is_active
FROM person
WHERE age = <int>;
我们将首先使用 age 列上的常规索引运行它,它必须执行索引和表读取,以检索 register_date 和 is_active 列的数据。然后,我们将使用覆盖索引进行再次练习,该索引是在 age 列上声明的,但包括了其他列。
第一个索引如下所示:
CREATE INDEX idx_person_age ON person(age);
第二个索引(覆盖索引)定义如下:
CREATE INDEX idx_person_age_cover ON person(age) INCLUDE (register_date,is_active);
为了验证结果的一致性,我们将使用不同数量的并发用户:20、100 和 200,来运行负载。结果绘制在下图中:
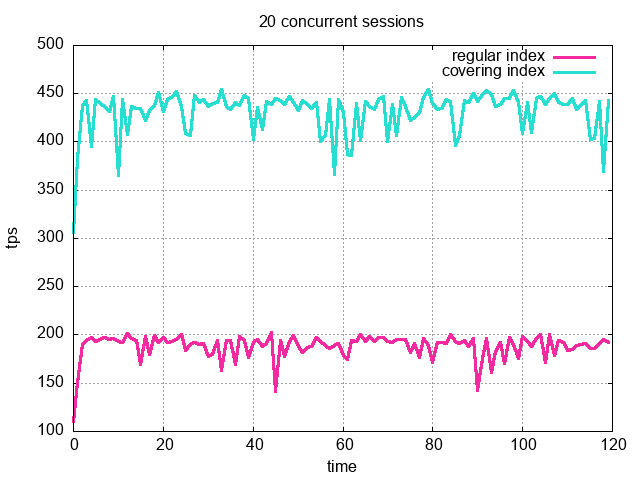
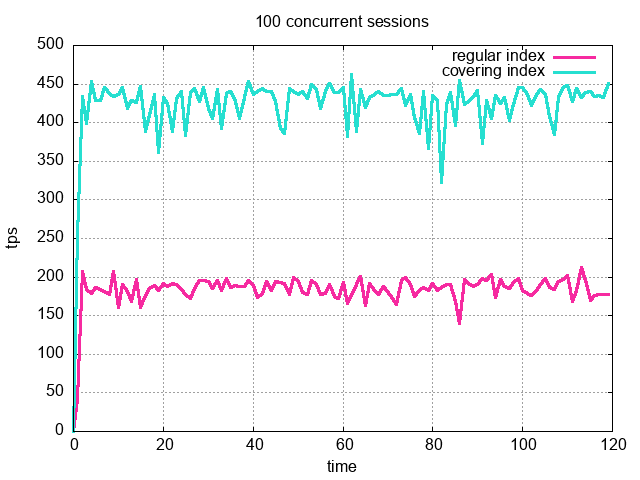
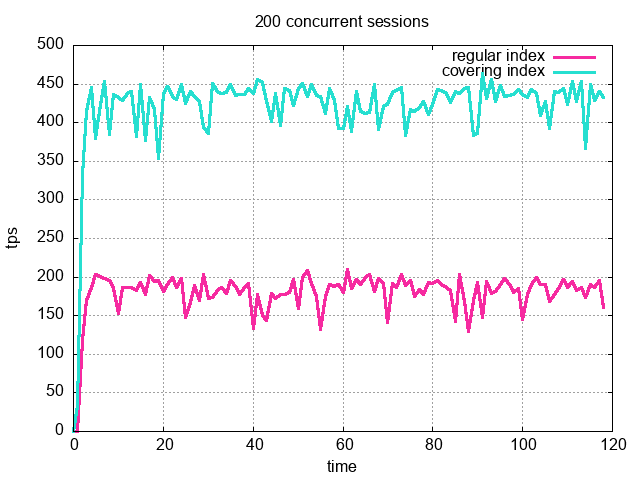
我们在所有三种情况下都得到了一致的结果。在所有这些结果中,利用只用索引的扫描的业务负载每秒执行的事务数(TPS),大约是使用索引扫描的业务负载执行的 2.25 倍。
只用索引扫描的要求
对大多数业务负载使用覆盖索引或复合索引,看起来是个好主意。但是,正如我们在文章中所看到的,必须满足一些条件才能获得这些好处:
- 索引类型必须支持只用索引的扫描方法。B 树索引总是支持的;GiST 和 SP-GiST 支持对某些运算符进行只用索引的扫描操作,但不是全部,并且其他任何索引类型都不支持只用索引的扫描。
- 查询必须只获取索引覆盖的列。在前面的测试中,查询要求提供 age、register_date 和 is_active 列,这些列包含在覆盖索引中。如果 SELECT 语句中有任何其他列,则规划器不会选择只用索引的扫描。
- PostgreSQL 扫描必须确保检索到的行对查询的快照是“可见的”。
可见性条件
前两个条件很容易理解;如果我们使用支持 Index-Only Scan 功能的索引类型,并且我们的查询只获取索引覆盖的列,那我们就已经准备好了。但是,第三个条件需要格外小心,以确保我们能获得好处。让我们展开来看下第三个条件。
只用索引的扫描的目标是,避免对表页(堆)的第二次读取访问,以节省该访问时间,并直接从索引中检索数据。尽管如此,PostgreSQL 必须确保索引数据与堆中的数据保持同步。
可见性信息不存储在索引中;它属于表页,因此乍一看表读取是不可避免的。但是,有一个解决方法:可见性映射表。如果给定页面中的所有行都足够老,对当前和未来的事务都可见,则会在可见性映射表中标记该页面的状态位。
从可见性映射表来验证行页面的可见性,比读取堆表的成本要低得多,因为它很小并且大部分时间都在缓存中。
换句话说,表中的数据更改越多,它在映射表中的可见性比率就越低。因此,为了确保我们能从只用索引的扫描功能中受益,我们需要验证该条件。
如何检查表的页面可见性
如 PostgreSQL 文档中所述,可见性映射表为每个表页仅存储两个位,一个用于指示可见性,另一个用于标记行是否已冻结。此文件不能作为一个传统文件进行检查;幸运的是,我们可以依靠 pg_visibility 扩展来实现此目的。
该扩展随任何基本 PostgreSQL 安装的 contrib 模块一起提供,因此要将其添加到数据库,直接执行下面语句即可:
CREATE EXTENSION pg_visibility;
使用与前面示例相同的表,我们可以按如下方式,来检查表 person 的页面:
SELECT * FROM pg_visibility_map('person');
blkno | all_visible | all_frozen
-------+-------------+------------
0 | t | t
1 | t | t
2 | t | t
[truncated…]
10202 | t | t
10203 | t | t
10204 | t | t
(10205 rows)
因此,我们可以看到为每个表页面的两个位设置的值,可以是 false 或 true。
一旦表开始在其数据中执行更新,相应页面的可见性状态位就会发生变化。例如,通过以下内容,我们可以知道 id 为 10000 的行所在的页面(blkno):
SELECT ctid, id FROM person WHERE id = 10000;
ctid | id
---------+-------
(204,4) | 10000
(1 row)
因此,我们可以检查第 204 页的可见性映射信息,然后更新该行并再次检查,如下:
SELECT * FROM pg_visibility_map('person')
WHERE blkno = 204;
blkno | all_visible | all_frozen
-------+-------------+------------
204 | t | t
(1 row)
UPDATE person SET register_date = now() WHERE id = 10000;
SELECT * FROM pg_visibility_map('person')
WHERE blkno = 204;
blkno | all_visible | all_frozen
-------+-------------+------------
204 | f | f
(1 row)
更新 id 为 10000 的行中的值后,可见性映射表中相应页面的 all_visible 列显示为 false。
随着不断针对表进行更新操作,可见性映射表将发生变化,标记为 all_visible 的页面数量将减少。
检查可见性百分比
了解可见性映射表变化的原因以及如何验证其内容后,我们可以检查可见页面的百分比,从而保持只用索引的扫描功能正常工作。
以下查询将显示标记为 all_visible 或 no_visible 的页面的百分比:
SELECT
x.pages::text,
round(avg(x.percent), 1)::int AS percentage
FROM (
SELECT
CASE WHEN all_visible THEN 'visible'
WHEN NOT all_visible THEN 'no_visible'
END pages,
100 * COUNT(all_visible) OVER (PARTITION BY all_visible) / COUNT(all_visible) OVER () AS percent
FROM
pg_visibility_map ('<table>')) x
GROUP BY
x.pages
UNION ALL
SELECT
'no_visible'::text,
0
WHERE NOT EXISTS (SELECT 1 FROM pg_visibility_map ('<table>') WHERE NOT all_visible);
在新加载的没有更新的表中,或者刚刚对表进行过 VACUUM 操作(VACUUM 过程会负责更新可见性映射表),我们可以获得类似于以下内容的输出:
pages | percentage
------------+------------
visible | 100
no_visible | 0
(2 rows)
当更新发生时,标记为可见的页面的百分比也会发生变化:
UPDATE person SET register_date = now() WHERE age < 15;
SELECT
x.pages::text,
round(avg(x.percent), 1)::int AS percentage
FROM (
SELECT
CASE WHEN all_visible THEN 'visible'
WHEN NOT all_visible THEN 'no_visible'
END pages,
100 * COUNT(all_visible) OVER (PARTITION BY all_visible) / COUNT(all_visible) OVER () AS percent
FROM
pg_visibility_map ('person')) x
GROUP BY
x.pages
UNION ALL
SELECT
'no_visible'::text,
0
WHERE NOT EXISTS (SELECT 1 FROM pg_visibility_map ('person') WHERE NOT all_visible);
pages | percentage
------------+------------
visible | 46
no_visible | 53
(2 rows)
PostgreSQL 将继续尝试执行只用索引的扫描,但是当页面在可见性映射表中标记为 “不可见” 时,它将不得不切换成不同的扫描方法,并从堆表中读取,从而失去所有性能提升。而且,标记为“不可见”的页面越多,只用索引的扫描尝试成功的可能性就越小。
在这种情况下,在对表进行 VACUUM 清理后,我们将再次看到所有页面都标记为 “可见的”:
VACUUM person;
SELECT
x.pages::text,
round(avg(x.percent), 1)::int AS percentage
FROM (
SELECT
CASE WHEN all_visible THEN 'visible'
WHEN NOT all_visible THEN 'no_visible'
END pages,
100 * COUNT(all_visible) OVER (PARTITION BY all_visible) / COUNT(all_visible) OVER () AS percent
FROM
pg_visibility_map ('person')) x
GROUP BY
x.pages
UNION ALL
SELECT
'no_visible'::text,
0
WHERE NOT EXISTS (SELECT 1 FROM pg_visibility_map ('person') WHERE NOT all_visible);
pages | percentage
------------+------------
visible | 100
no_visible | 0
(2 rows)
结论
只用索引的扫描无疑是为我们的查询获得最佳性能的绝佳方法;但是,在添加复合索引或覆盖索引之前,我们还需要注意表在更新和页面可见性方面的行为。
借助 pg_visibility 扩展和一些查询(如我们在本文中看到的查询),我们可以监控我们的表,并确定它们是否适合使用只用索引的扫描,或者是否可以针对 VACUUM 节奏或业务负载类型进行一些调整。