十月 18, 2024
摘要:在本教程中,您将会学习到 PostgreSQL 中的并行 VACUUM 的工作原理。
目录
VACUUM 是最重要的一个功能,它可以回收表和索引中已删除的元组。如果没有 vacuum,表和索引的大小将会继续无限增长。本教程介绍了 PostgreSQL 13 中新引入的 VACUUM 命令的 PARALLEL 选项。
VACUUM 处理阶段
在深入讨论新选项之前,让我们回顾一下 vacuum 工作原理的细节。
VACUUM(无 FULL 选项)由五个阶段组成。例如,对于具有两个索引的表,其工作方式如下:
- 堆扫描阶段
- 从顶部开始扫描表,并在内存中收集垃圾元组。
- 索引 vacuum 阶段
- 逐个对两个索引进行 vacuum。
- 堆表 vacuum 阶段
- 对堆(表)进行 vacuum。
- 索引清理阶段
- 逐个清理这两个索引。
- 堆截断阶段
- 截断表末尾的空页。
在堆扫描阶段,vacuum 可以使用可见性映射表跳过已知没有任何垃圾的页面的处理,而在索引 vacuum 阶段和索引清理阶段,根据索引访问方法,需要进行整个索引扫描。
例如,btree 索引是最常用的索引类型,它需要扫描整个索引,来删除垃圾元组并执行索引清理。由于 vacuum 始终由单个进程执行,因此索引会逐个处理。在尤其是大表上执行 vacuum 的时间较长,这通常会让用户感到烦恼。
PARALLEL 选项
为了解决这个问题,PostgreSQL 13 中引入了 PARALLEL 选项。使用此选项,vacuum 可以使用并行工作进程,来执行索引 vacuum 阶段和索引清理阶段。并行 vacuum 工作进程在进入索引 vacuum 阶段或索引清理阶段之前启动,并在该阶段结束时退出。一个索引会分配一个单独的工作进程。在 autovacuum 中,并行 vacuum 始终处于禁用状态。
不带整数参数选项的 PARALLEL 选项,会根据表上的索引数自动计算并行度。
VACUUM (PARALLEL) tbl;
由于领导进程始终处理一个索引,因此并行工作进程的最大数量将为(表中的索引数 – 1),进一步限制为 max_parallel_maintenance_workers。目标索引必须大于或等于 min_parallel_index_scan_size。
PARALLEL 选项允许我们通过传递非零整数值来指定并行度。以下示例使用 3 个工作进程,总共有 4 个进程并行运行。
VACUUM (PARALLEL 3) tbl;
默认情况下,PARALLEL 选项处于启用状态;要禁用并行 vacuum,请将 max_parallel_maintenance_workers 设置为 0,或指定PARALLEL 0。
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
查看 VACUUM VERBOSE 输出,我们可以看到一个工作进程正在处理索引。
输出为 “by parallel worker” 的信息是由工作进程产生的。
VACUUM (PARALLEL, VERBOSE) tbl;
INFO: vacuuming "public.tbl"
INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2)
INFO: scanned index "i1" to remove 112834 row versions
DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s
INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker
DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s
INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker
DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s
INFO: "tbl": removed 112834 row versions in 112834 pages
DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s
INFO: index "i1" now contains 150000000 row versions in 411289 pages
DETAIL: 112834 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: index "i2" now contains 150000000 row versions in 411289 pages
DETAIL: 112834 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: index "i3" now contains 150000000 row versions in 411289 pages
DETAIL: 112834 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046
There were 444 unused item identifiers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s.
VACUUM
索引访问方法与并行度
VACUUM 并不总会并行执行索引 vacuum 阶段和索引清理阶段。如果索引大小较小,或者如果已知该过程可以快速完成,则启动和管理并行工作进程以进行并行化的成本反而会产生开销。根据索引访问方法及其大小,最好不要通过并行 vacuum 工作进程来执行这些阶段。
例如,在对足够大的 btree 索引执行 vacuum 操作时,索引的索引 vacuum 阶段可以由并行 vacuum 工作进程执行,因为它始终需要扫描整个索引,而如果未执行索引 vacuum(即,表上没有垃圾),则索引清理阶段由并行 vacuum 工作进程执行。这是因为 btree 索引在索引清理阶段需要收集索引统计信息,该统计信息在索引 vacuum 阶段也会收集。另一方面,哈希索引不需要在索引清理阶段对索引进行扫描。
为了支持不同类型的索引 vacuum 策略,索引访问方法的开发者,可以通过为IndexAmRoutine结构的amparallelvacuumoptions字段设置标志,来指定这些行为。可用的标志如下:
- VACUUM_OPTION_NO_PARALLEL(默认)
- 在两个阶段中,并行 vacuum 均被禁用。
- VACUUM_OPTION_PARALLEL_BULKDEL
- 索引 vacuum 阶段可以并行进行。
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- 如果尚未执行索引 vacuum 阶段,则可以并行执行索引清理阶段。
- VACUUM_OPTION_PARALLEL_CLEANUP
- 即使索引 vacuum 阶段已经处理了索引,也可以并行执行索引清理阶段。
下表显示了 PostgreSQL 内置的索引访问方法对并行 vacuum 的支持情况。
| nbtree | hash | gin | gist | spgist | brin | bloom | |
|---|---|---|---|---|---|---|---|
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
有关更多详细信息,请参见 ‘src/include/command/vacuum.h’。
性能验证
下面是在一台普通工作电脑(Core i7 2.6GHz、16GB RAM、512GB SSD)上,对并行 vacuum 做的性能测试评估。表大小为 6GB,有 8 个 3GB 索引。关系总大小为 30GB,这是无法完全存放在机器内存中的。对于每次测试,在 vacuum 后会均匀地弄脏百分之几的表,然后在改变并行度的同时进行 vacuum。下图显示了 vacuum 执行时间。
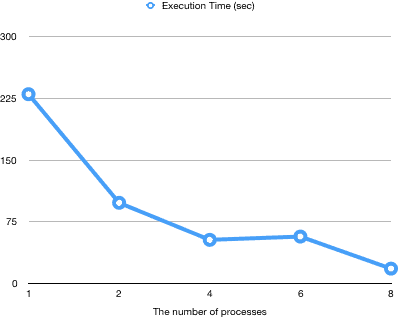
在所有测试中,索引 vacuum 的执行时间占总执行时间的 95% 以上。因此,索引 vacuum 阶段的并行化有助于大大缩短 vacuum 执行时间。