六月 24, 2024
摘要:在本教程中,您将了解 PostgreSQL 中的查询规划。
目录
介绍
SQL 是一种声明性语言:一个查询会指定要检索的内容,但不指定如何检索它。
任何查询都可以通过多种方式来执行。在解析树中的每个操作,都有多个可选的执行方式。例如,您可以通过读取整个表并丢弃不需要的行,来检索表中的特定记录,也可以使用索引来查找与查询匹配的行。数据集始终成对连接。连接顺序的变化会产生大量可选的执行路径。然后有多种方法可以将两组行连接在一起。例如,您可以逐个访问第一个集合中的行,然后在另一个集合中查找匹配的行,或者可以先对两个集合进行排序,然后将它们合并在一起。不同的方法在某些情况下效果更好,而在其他情况下效果更差。
最优计划的执行速度,可能比非最优计划要快几个数量级。这也就是为什么优化解析查询的规划器是系统中最复杂的组件之一。
计划树
执行计划也可以表示为一棵树,但其节点是数据上的物理操作,而不是逻辑操作。
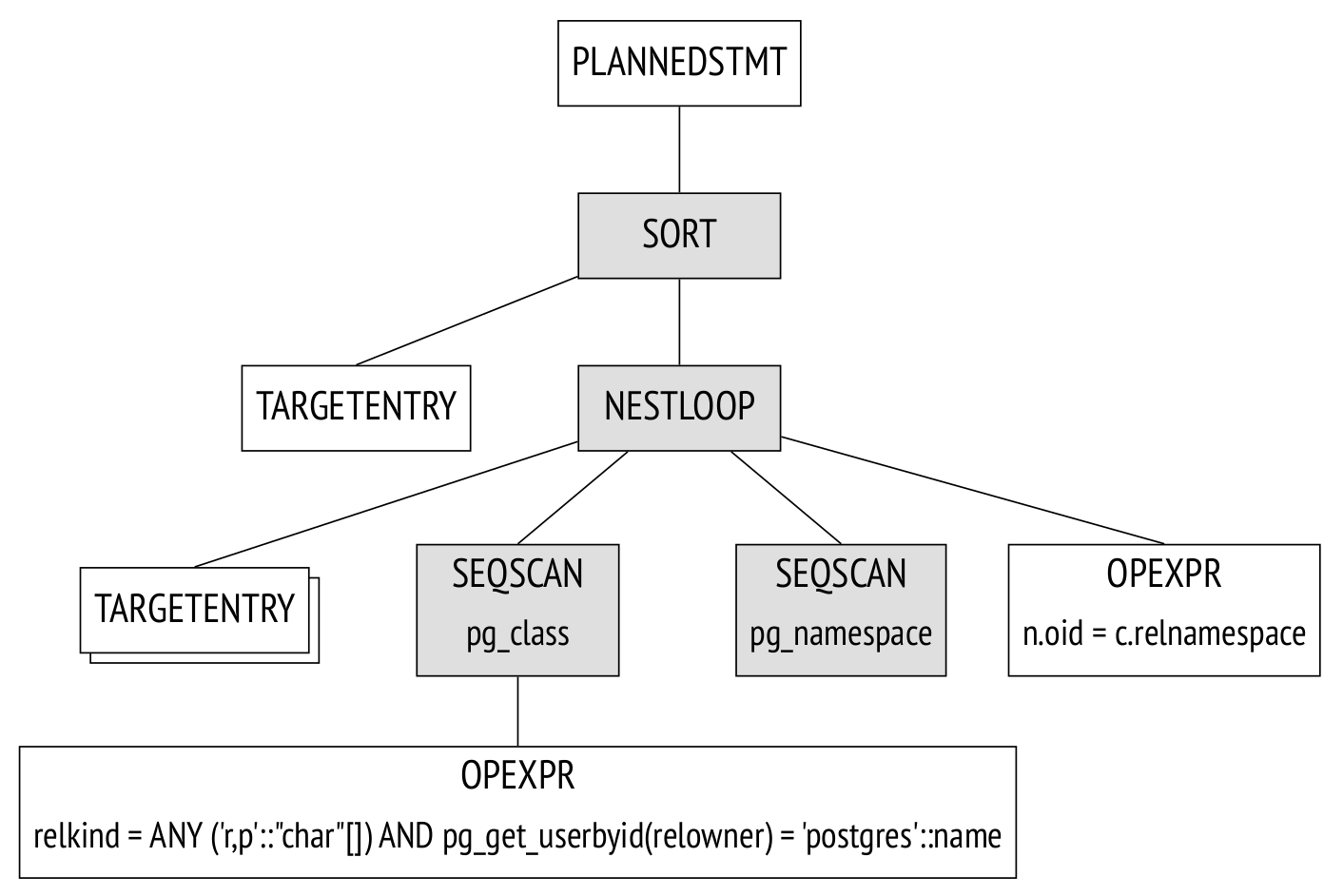
如果参数 debug_print_plan 处于开启状态,则完整的计划树将显示在服务器消息日志中。这是非常不切实际的,因为日志会非常杂乱。更方便的选择是使用 EXPLAIN 命令:
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Sort (cost=21.03..21.04 rows=1 width=128)
Sort Key: c.relname
-> Nested Loop Left Join (cost=0.00..21.02 rows=1 width=128)
Join Filter: (n.oid = c.relnamespace)
-> Seq Scan on pg_class c (cost=0.00..19.93 rows=1 width=72)
Filter: ((relkind = ANY ('{r,p}'::"char"[])) AND (pg_get_userbyid(relowner) = 'postgres'::name))
-> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 width=68)
(7 rows)
上图显示了计划树的主要节点。相同的节点在 EXPLAIN 输出中用箭头标记。
Seq Scan 节点表示表读取操作,而 Nested Loop 节点表示连接操作。这里有两点值得注意:
- 其中一个初始表从计划树中消失了,因为规划器发现处理查询不需要并将其删除。
- 每个节点旁边都有估计的要处理的行数和处理的成本。
计划搜索
为了找到最佳计划,PostgreSQL 采用了基于成本的查询优化器。优化器会检查各种可用的执行计划,并估计所需的资源量,例如 I/O 操作和 CPU 计算量。计算出来的估计值转换为任意单位,称为计划成本。总成本最低的计划会被选择进行执行。
问题在于,随着连接数量的增加,可能的计划数量会呈指数级增长,即使对于相对简单的查询,也无法逐一筛选所有计划。因此,动态规划和启发式算法会用于限制搜索范围。这允许在合理的时间内,准确地解决查询中含有很多表的问题,但不能保证所选计划是真正最优的,因为规划器采用了简化的数学模型,并且可能会使用不精确的初始数据。
连接顺序
可以以特定方式来构建查询,以显著缩小搜索范围(但可能会错过找到最佳计划的机会):
- 公共表表达式通常会与主查询分开单独优化。从版本 12 开始,可以使用 MATERIALIZE 子句强制执行此操作。
- 来自非 SQL 函数的查询会与主查询分开单独优化。(在某些情况下,SQL 函数可以内联到主查询中。)
- join_collapse_limit 参数与显式 JOIN 子句,以及 from_collapse_limit 参数与子查询,可一起定义某些连接的顺序,具体取决于查询的语法。
最后一条可能需要解释。下面的查询在 FROM 子句中调用了多个表,没有显式的连接:
SELECT ...
FROM a, b, c, d, e
WHERE ...
这是该查询的解析树:
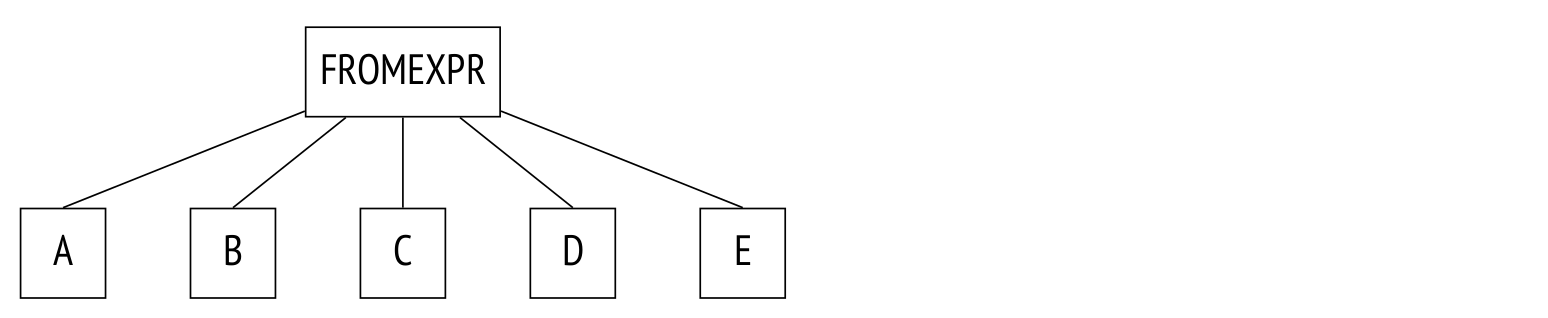
在此查询中,规划器将考虑所有可能的连接顺序。
在下一个示例中,一些连接通过 JOIN 子句进行了显式的定义:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
解析树反映了这一点:
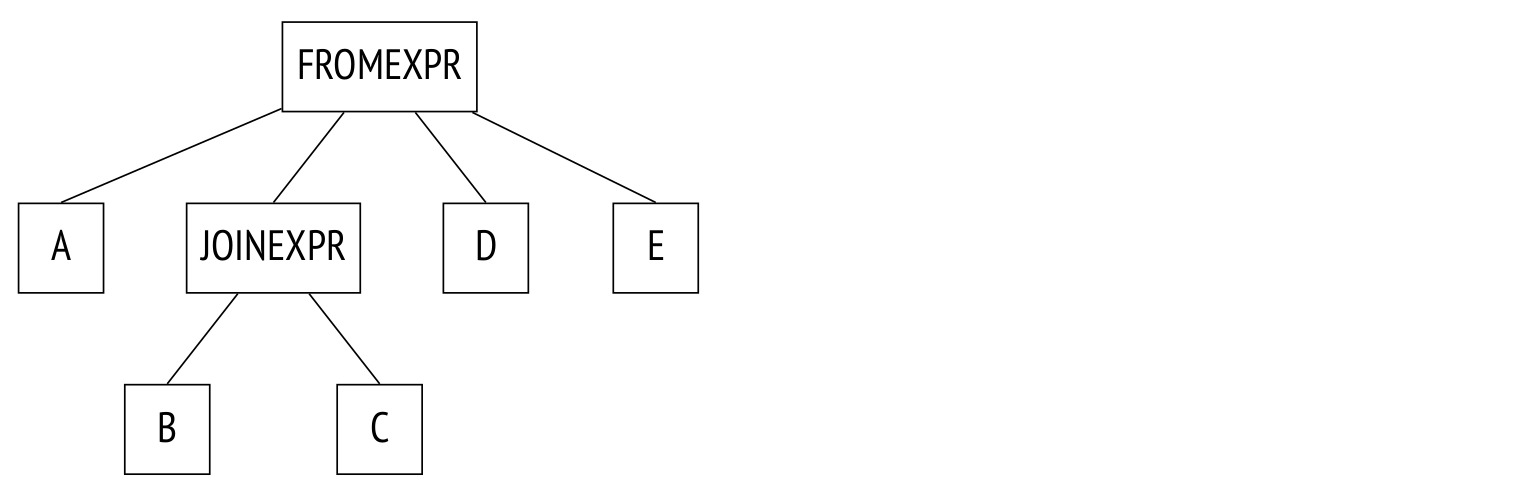
规划器折叠连接树,有效地将其转换为上一个示例中的树。该算法以递归方式遍历树,并将每个 JOINEXPR 节点替换为其组件的平铺列表。
但是,只有当生成的平铺列表包含不超过 join_collapse_limit 数目的元素(默认为 8 个)时,才会发生这种“扁平化”。在上面的示例中,如果 join_collapse_limit 设置为 5 或更小,则 JOINEXPR 节点不会折叠。对于规划器来说,这意味着两件事:
- 表 B 必须连接到表 C(反之亦然,一个配对中的连接顺序不受限制)。
- 表 A、D、E,和 B 到 C 的连接可以按任意顺序连接。
如果 join_collapse_limit 设置为 1,则将保留任何显式的 JOIN 顺序。
请注意,无论 join_collapse_limit 为何值,FULL OUTER JOIN 操作都不会折叠。
参数 from_collapse_limit(默认为 8)以类似的方式限制子查询的扁平化。子查询似乎与连接没有太多共同之处,但是当它进入到解析树级别时,相似性是显而易见的。
示例:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
这是树:
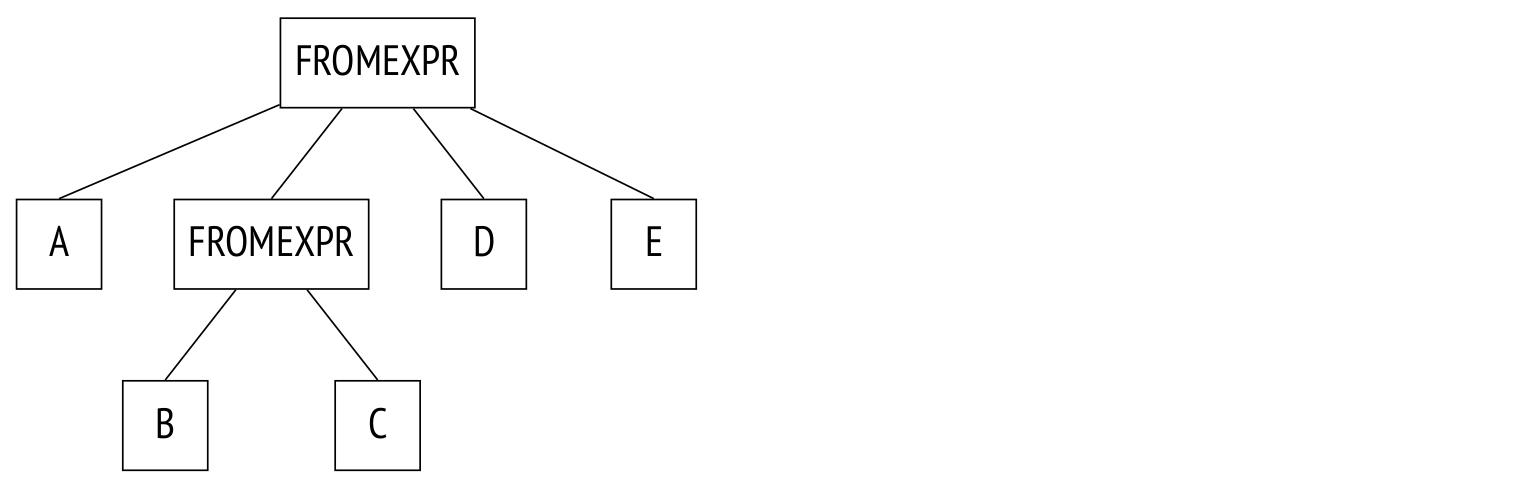
这里唯一的区别是,JOINEXPR 节点被替换为了 FROMEXPR(因此参数名称为 FROM)。
基因搜索
每当生成的扁平化计划树最终包含太多相同级别的节点(表或连接结果)时,规划时间可能会飙升,因为每个节点都需要单独的优化。如果参数 geqo 处于开启状态(默认为开启),则每当同级节点数量达到 geqo_threshold(默认为 12)时,PostgreSQL 将切换到基因搜索。
基因搜索比动态规划方法快得多,但它并不能保证找到最好的计划。该算法有许多可调整的选项,但这应该是另一篇文章的主题。
选择最佳计划
最佳计划的定义因期望的用途而异。当需要完整输出时(例如,生成报表),计划必须优化与查询匹配的所有行的检索。另一方面,如果您只想查看前几行匹配的行(例如,在屏幕上显示),则最佳计划可能完全不同。
PostgreSQL 通过计算两个成本构成来解决这个问题。它们显示在查询计划输出中的 “cost” 一词之后:
Sort (cost=21.03..21.04 rows=1 width=128)
第一个部分,启动成本,是准备执行节点的成本;第二个部分,总成本,表示节点执行的总成本。
选择计划时,规划器首先检查是否正在使用游标(可以使用 DECLARE 命令设置游标,或在 PL/pgSQL 中显式声明)。如果没有,规划器将假定需要全部输出,并选择总成本最低的计划。
否则,如果在使用游标,则规划器将选择一个计划,该计划以最佳方式检索等于匹配行总数的 cursor_tuple_fraction(默认为 0.1)的行数。或者,更具体地说,具有最低值
启动成本 + cursor_tuple_fraction × (总成本 − 启动成本)。
成本计算过程
要估算一个计划的成本,必须单独估算其每个节点。节点成本取决于节点类型(从表中直接读取的成本远低于对表数据进行排序的成本)和处理的数据量(通常,数据越多,成本越高)。虽然节点类型是立即就知道的,但要评估数据量,我们首先需要估计节点的基数(输入行的数量)和选择率(剩余用于输出的行的比例)。为此,我们需要数据的统计信息:表大小、跨列的数据分布。
因此,优化依赖于准确的统计信息,这些统计信息由自动分析进程收集和保持最新状态。
如果准确估计了每个计划节点的基数,则计算的总成本通常与实际成本匹配。常见的规划偏差通常是由基数和选择率估计不正确造成的。这些错误是由不准确、过时或不可用的统计数据引起的,并且在较小程度上,也会由规划器所基于的固有不完善的模型引起。
基数估算
基数估算是递归执行的。节点基数使用两个值计算:
- 节点的子节点的基数,或输入行数。
- 节点的选择率,或输出行与输入行的比例。
基数是这两个值的乘积。
选择率是介于 0 和 1 之间的数字。接近零的选择率值称为高选择率,接近 1 的值称为低选择率。这是因为高选择率消除了较高比例的行,而较低的选择率值会降低阈值,因而丢弃的行更少。
具有数据访问方法的叶节点会首先处理。这就是表大小等统计信息的用武之地。
应用于一个表的条件的选择率取决于条件类型。在最简单的形式中,选择率可以是一个恒定值,但规划器会试图使用所有可用信息来产生最准确的估计。最简单条件的选择率估计会作为基础,使用布尔运算构建的复杂条件,可以使用以下简单公式进行进一步计算:
selx and y = selx sely
selx or y = 1−(1−selx)(1−sely) = selx + sely − selx sely。
在这些公式中,x 和 y 被认为是独立的。如果它们相关,公式仍会被使用,但估计值会不太准确。
对于连接的基数估计,会计算两个值:笛卡尔乘积的基数(两个数据集的基数的乘积)和连接条件的选择率,这反过来又取决于条件类型。
其他节点类型(如排序或聚合节点)的基数计算方式类似。
请注意,较低节点中的基数计算错误会向上传播,导致成本估算不准确,并最终选择出次优的计划。更糟糕的是,规划器只有表上的统计数据,而没有连接结果的统计数据。
成本估算
成本估算过程也是递归的。子树的成本包括其子节点的成本加上父节点的成本。
节点成本的估算基于其执行的操作的数学模型。已经计算过的基数会用作输入。估算过程会计算启动成本和总成本。
某些操作不需要任何准备,可以立即开始执行。对于这些操作,启动成本将为零。
其他操作可能具有前提条件。例如,排序节点通常需要其子节点中的所有数据才能开始操作。这些节点的启动成本不为零。即使下一个节点(或客户端)只需要一行输出,也必须付出此成本。
成本是规划器的最佳估计。任何规划错误都会影响到成本与实际执行时间的相关性。成本评估的主要目的是,允许规划器在相同条件下比较同一查询的不同执行计划。在任何其他情况下,按成本比较查询(更糟糕的是,对不同的查询)是毫无意义和错误的。比如,考虑下由于统计信息不准确而被低估的成本。更新统计信息 - 成本可能会发生变化,但估算会变得更加准确,并且计划最终也会得到改进。